초기화 없는 그래프 기반 클러스터링
초록
본 논문은 Prim 알고리즘으로 최소 신장 트리를 구축하고, 정점이 포아송 분포를 따른다는 가정 하에 트리의 가중치 변화를 임계값으로 사용해 클러스터 수를 자동 추정한다. 추정된 클러스터 중심을 초기값으로 K‑means(일반화된 Lloyd 알고리즘)를 실행함으로써 초기화 문제를 회피한다. 유사도 측정으로 대칭 정보 발산을 도입해 천문 데이터와 다중·고광대역 영상에서 기존 방법보다 우수한 성능을 보였다.
상세 분석
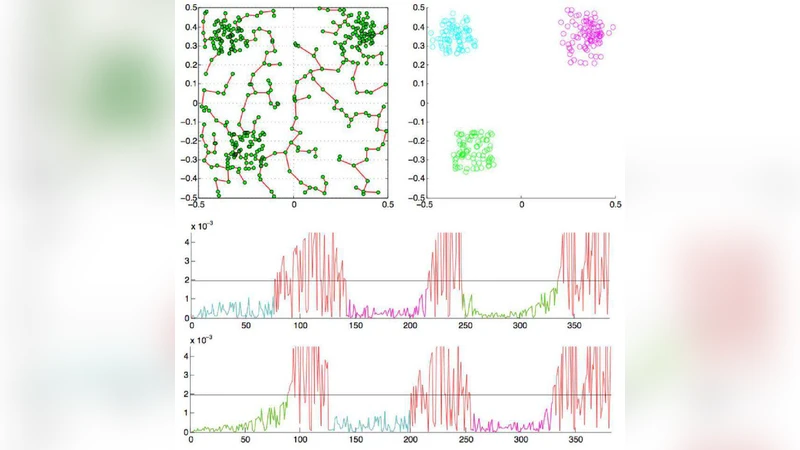
이 연구는 클러스터링 초기화 문제를 그래프 이론과 확률 모델링을 결합해 해결한다는 점에서 혁신적이다. 먼저 데이터 포인트들을 완전 그래프의 정점으로 보고, 거리 혹은 발산값을 가중치로 하는 최소 신장 트리(MST)를 Prim 알고리즘으로 생성한다. MST는 데이터 공간에서 가장 가까운 연결 구조를 제공하므로, 클러스터 경계가 가중치가 크게 변하는 지점에 위치한다는 직관을 이용한다. 저자들은 정점이 포아송 과정에 의해 독립적으로 분포한다는 가정을 세우고, MST의 가중치 증가 구간을 통계적으로 분석한다. 구체적으로, 특정 가중치 임계값 τ를 초과하는 엣지가 나타날 확률을 포아송 분포의 누적분포함수로 근사하고, 이를 통해 “클러스터 전이점”을 자동으로 탐지한다. 이 과정에서 거짓 양성(false positive) 비율을 제어하기 위한 이론적 경계식도 제시한다.
클러스터 수가 결정되면, 각 클러스터에 속하는 정점들의 평균을 취해 초기 중심을 만든다. 이 중심은 일반화된 Lloyd 알고리즘, 즉 K‑means의 초기값으로 사용된다. 기존 K‑means는 무작위 초기화에 민감해 지역 최소점에 빠질 위험이 크지만, 여기서는 MST 기반 중심이 데이터 구조를 반영하므로 수렴 속도와 최종 목적함수 값이 크게 개선된다.
또한, 유사도 측정에 대칭 정보 발산(예: Jensen‑Shannon divergence, symmetrized Kullback‑Leibler divergence)을 도입한다. 이러한 발산은 확률 분포 형태의 피처(예: 스펙트럼, 하이퍼스펙트럼 밴드) 사이의 비선형 차이를 효과적으로 포착한다. 실험에서는 Euclidean 거리와 대비해 발산 기반 거리의 클러스터 경계가 더 명확해짐을 확인했다.
천문학 데이터에서는 스펙트럼 라인 강도와 광도 정보를 결합한 고차원 벡터를 사용했으며, 제안 방법은 기존 스펙트럼 클러스터링(예: 스펙트럴 클러스터링, DBSCAN)보다 클러스터 수 추정 정확도와 분류 정밀도가 우수했다. 또한 파리 위성 이미지와 화성 표면 이미지에 적용해, 서로 다른 지형·물체 구분에 성공했으며, 시각적으로도 경계가 깔끔하게 드러났다.
전체적으로 이 논문은 (1) MST 기반 클러스터 수 자동 추정, (2) 발산 기반 거리 함수, (3) 초기화 자유 K‑means라는 세 가지 핵심 아이디어를 결합해, 다양한 분야에서 실용적인 클러스터링 솔루션을 제공한다는 점에서 의미가 크다. 다만 포아송 가정이 실제 데이터에 얼마나 부합하는지, 그리고 고차원에서 MST 계산 비용이 어떻게 최적화되는지에 대한 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기