모래 위에 건설
초록
신뢰성 없는 대규모 구성요소가 시스템에 도입되면서, 동기식 백업이 비현실적이 되고 비동기 상태 캡처가 일반화된다. 이때 약속은 확률적이며, 애플리케이션은 최종 일관성을 보장해야 한다. 논문은 이러한 흐름을 되짚고, 새로운 일관성 모델과 설계 패턴을 제시한다.
상세 분석
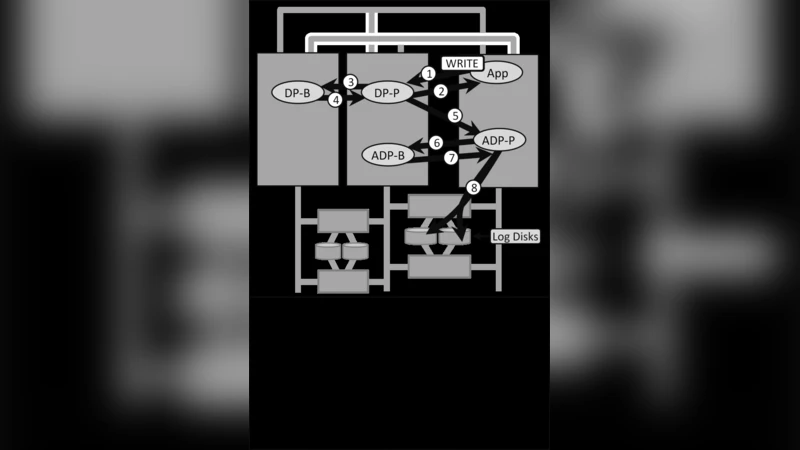
본 논문은 신뢰성 확보를 위한 전통적인 복제·백업 메커니즘이, 구성요소의 규모가 커짐에 따라 비효율적으로 변모하는 과정을 심도 있게 분석한다. 초기에는 미러 디스크나 ECC와 같은 미세한 오류 정정 장치가 주를 이루었으며, 이러한 장치는 장애가 발생해도 애플리케이션에 투명하게 작동했다. 그러나 스토리지 풀, 전체 서버, 혹은 데이터센터 수준까지 불안정성이 확대되면서, 백업에 대한 동기식 확인(latency)이 시스템 응답성을 크게 저해한다는 점을 지적한다.
이에 대한 해결책으로 제시된 것이 “비동기 상태 캡처(asynchronous state capture)”이다. 프라이머리 노드가 작업을 수락하고 즉시 응답을 반환한 뒤, 백업에게 복제 정보를 전송하는 과정을 별도 스레드나 로그 기반 복제 시스템에 위임한다. 이 모델의 핵심은 두 가지 함의이다. 첫째, 프라이머리의 약속은 확률적이며, 장애 발생 시 백업이 최신 상태를 놓칠 위험이 존재한다. 따라서 “무조건적인 보장”이 불가능하고, 시스템은 “가능성 기반”의 서비스 수준 계약(SLA)을 제공한다. 둘째, 작업 순서와 일관성이 보장되지 않으므로 애플리케이션은 최종 일관성(eventual consistency)을 스스로 구현해야 한다. 이는 작업이 중복되거나 재전송될 때 멱등성(idempotence)과 충돌 해결 메커니즘을 설계해야 함을 의미한다.
논문은 이러한 비동기 모델이 실제 운영 환경에서 어떻게 적용되는지를 사례 연구와 함께 제시한다. 예를 들어, 대규모 NoSQL 데이터베이스의 로그 기반 복제, 분산 메시지 큐의 ‘at‑least‑once’ 전달, 그리고 클라우드 스토리지 서비스의 ‘write‑behind’ 캐시 전략을 분석한다. 각 사례는 비동기 복제의 장점(낮은 지연, 높은 가용성)과 단점(데이터 손실 가능성, 복구 복잡도)을 균형 있게 보여준다.
또한, 논문은 새로운 설계 패턴을 제안한다. 첫째, “확률적 약속 인터페이스”를 통해 API 수준에서 성공 여부와 신뢰 수준을 명시한다. 둘째, “상태 캡처 토큰”을 도입해 백업이 언제 어떤 상태를 받아들였는지 추적 가능하도록 한다. 셋째, “충돌 해결 플러그인”을 표준화해 애플리케이션이 일관성 정책을 선언적으로 선택하도록 지원한다. 이러한 패턴은 기존 시스템에 최소한의 침투로 비동기 복제를 도입하고, 개발자가 일관성 요구사항을 명확히 표현하도록 돕는다.
마지막으로, 향후 연구 방향으로는 확률적 모델을 수학적으로 정량화하는 방법, 머신러닝 기반 장애 예측을 통한 사전 백업 전송, 그리고 다중 백업 간의 협업 복제 프로토콜을 제시한다. 전체적으로 논문은 “신뢰성 없는 큰 구성요소 위에 신뢰성을 쌓는다”는 역설적 상황을 인식하고, 이를 관리하기 위한 체계적 접근법을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기