소셜 컴퓨팅을 위한 무한 확장 스토리지 SCADS
초록
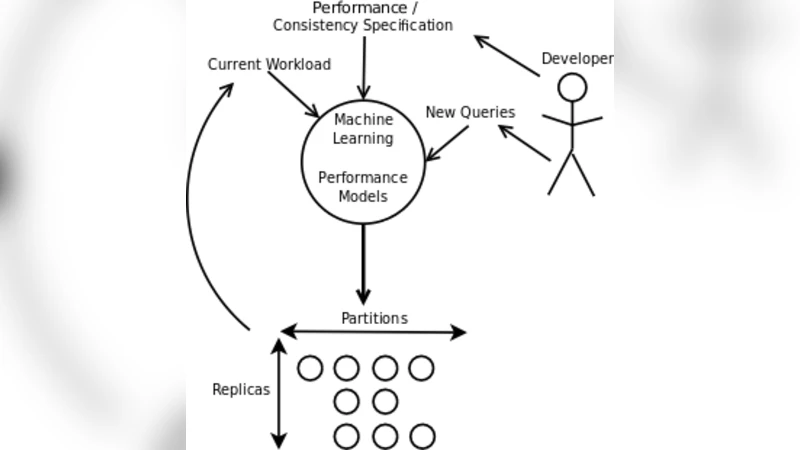
SCADS는 페이스북·플리커·Yelp 같은 Web 2.0 애플리케이션의 특성을 고려해, 일관성 요구를 선언형으로 지정하고, 사전 계산된 쿼리를 중심으로 높은 확장성을 제공하는 분산 스토리지 시스템이다. 개발자는 애플리케이션 별 일관성 수준을 선언하고, 시스템은 유틸리티 컴퓨팅 자원을 자동으로 할당·조정하며, 머신러닝 모델을 이용해 새로운 쿼리의 성능 영향을 사전에 예측한다.
상세 분석
SCADS는 기존 키‑값 스토어가 제공하는 단순한 GET/PUT 인터페이스를 넘어, 제한된 형태의 SQL‑유사 선언적 질의 언어를 지원한다는 점에서 차별화된다. 핵심 아이디어는 “애플리케이션‑특정 일관성 요구”를 개발자가 명시하도록 하는데, 이는 전통적인 강력한 일관성(예: ACID) 대신 “최대 지연 시간”이나 “최소 복제 수” 같은 SLA 기반 제약을 의미한다. 이러한 제약은 시스템이 데이터를 파티셔닝하고 복제할 때, 각 파티션에 대해 독립적인 스케일‑업·스케일‑다운 정책을 적용할 수 있게 해준다.
SCADS는 유틸리티 컴퓨팅(클라우드 인스턴스, 스팟 인스턴스 등)을 활용해 비용 효율적인 자원 할당을 자동화한다. 워크로드가 급증하면 추가 노드를 동적으로 프로비저닝하고, 사용량이 감소하면 불필요한 인스턴스를 해제한다. 이 과정에서 시스템은 “예측 가능한 비용·성능 모델”을 유지하기 위해 머신러닝 기반 모니터링 엔진을 운용한다. 엔진은 과거 쿼리 실행 로그, 파티션 크기, 네트워크 지연 등을 입력으로 받아, 새로운 질의가 배포될 때 필요한 복제 수와 스토리지 용량을 사전에 추정한다.
데이터 모델은 기본적으로 “키‑값 + 부가 메타데이터” 형태이며, 부가 메타데이터는 사전 정의된 인덱스와 집계 뷰를 통해 빠른 읽기 전용 질의를 지원한다. 쓰기 경로는 “쓰기‑전‑읽기” 패턴을 허용해, 최신 데이터가 즉시 읽히지 않아도 되는 경우에 높은 쓰기 처리량을 달성한다. 또한, SCADS는 파티션 간 데이터 이동을 최소화하기 위해 “데이터 로컬리티 기반 파티셔닝” 전략을 채택한다. 이는 사용자 행동이 지리적·사회적 클러스터를 형성한다는 가정에 기반한다.
한계점으로는 완전한 ad‑hoc 쿼리를 지원하지 못한다는 점, 일관성 선언이 복잡한 트랜잭션 시나리오에 적용하기 어려울 수 있다는 점, 그리고 머신러닝 모델의 정확도가 워크로드 변동성에 크게 의존한다는 점을 들 수 있다. 그럼에도 불구하고, SCADS는 대규모 소셜 서비스가 요구하는 “높은 쓰기 처리량 + 제한된 읽기 지연 + 비용 효율적인 자동 스케일링”을 만족시키는 실용적인 설계라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기