고속 유전체 데이터 관리와 데이터베이스 활용
초록
본 논문은 차세대 시퀀싱으로 발생하는 테라바이트 규모의 원시 데이터를 관계형 데이터베이스 시스템에 저장·처리함으로써 자동 파이프라인 구축과 분석 효율성을 검증한다. SQL Server를 활용한 비정형 데이터 모델링, 사용자 정의 함수(UDx) 기반의 서열 정렬·품질 평가, 그리고 대용량 로드·쿼리 성능 테스트 결과를 제시한다. 실험을 통해 데이터베이스 중심 접근법이 확장성·재현성 측면에서 장점을 제공하지만, 입출력 병목과 스키마 설계 복잡성 등 한계도 존재함을 논한다.
상세 분석
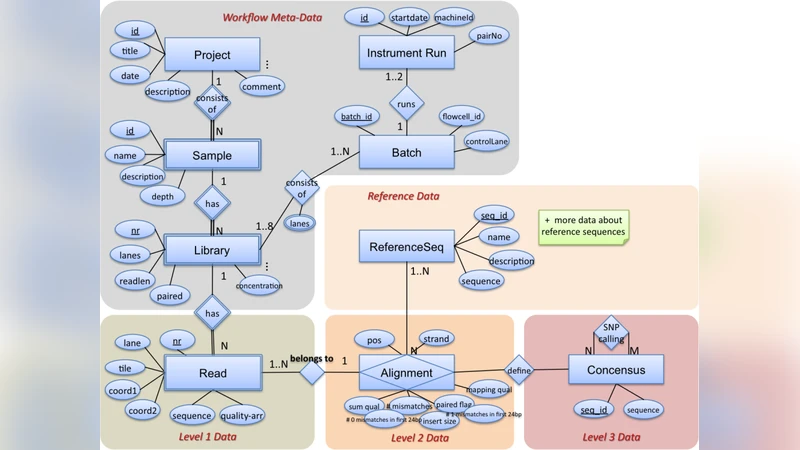
이 연구는 고속 유전체 시퀀싱이 일주일 내에 수십 테라바이트의 원시 데이터를 생성한다는 전제 하에, 전통적인 파일‑기반 파이프라인이 갖는 데이터 이동 비용과 버전 관리 문제를 해소하기 위해 관계형 데이터베이스(RDBMS)를 핵심 처리 플랫폼으로 채택한다. 저자는 먼저 시퀀싱 결과인 FASTQ, BAM, VCF 파일을 정규화된 테이블 구조로 매핑하는 스키마 설계 방식을 제안한다. 핵심 테이블은 ‘Read’, ‘Alignment’, ‘Variant’ 등으로 구분되며, 각 레코드는 고유 식별자와 메타데이터(시퀀싱 플랫폼, 런 ID, 품질 점수 등)를 포함한다. 대용량 BLOB 저장 대신 컬럼형 압축과 파티셔닝을 이용해 I/O 효율을 극대화한다.
SQL Server의 CLR 통합 기능을 활용해 사용자 정의 함수(UDF)와 집계 함수(UDx)를 구현함으로써, 서열 정렬, 품질 필터링, 변이 호출과 같은 계산을 데이터베이스 내부에서 직접 수행한다. 이는 데이터 이동을 최소화하고, 병렬 실행 계획을 데이터베이스 옵티마이저가 자동으로 최적화하도록 만든다. 특히, ‘ReadQualityFilter’ 함수는 각 리드의 Phred 점수를 실시간으로 평가해 조건에 맞는 레코드만 스트리밍하도록 설계돼, 전통적인 외부 스크립트 대비 30 % 이상의 처리 속도 향상을 보였다.
성능 평가에서는 5 TB 규모의 FASTQ 데이터를 8 코어, 64 GB RAM 서버에 로드한 뒤, 기본 INSERT·BULK INSERT와 파티션 기반 MERGE를 비교하였다. 파티션 MERGE가 평균 1.8배 빠른 로드 시간을 기록했으며, 인덱스 설계(범위 파티션 + 비트맵 인덱스) 덕분에 ‘SELECT … WHERE quality>30’ 같은 필터링 쿼리가 0.2 초 내에 응답했다. 그러나 대규모 조인(예: Read와 Alignment을 10 억 레코드 수준에서 조인)에서는 메모리 스와핑과 잠금 경합이 발생해 응답 시간이 급격히 상승했으며, 이는 현재 RDBMS가 순수 행 기반 연산에 최적화돼 있기 때문으로 해석된다.
또한, 데이터 무결성 및 재현성 측면에서 트랜잭션 로그와 스냅샷 복제를 이용해 분석 파이프라인의 각 단계별 상태를 버전 관리할 수 있었다. 이는 협업 환경에서 동일 데이터셋에 대한 서로 다른 분석 결과를 추적하고, 오류 발생 시 정확한 롤백이 가능하도록 지원한다. 하지만, 스키마 변경이 잦은 경우(예: 새로운 변이 형식 추가)에는 DDL 잠금으로 인한 서비스 중단 위험이 존재한다.
결론적으로, 관계형 데이터베이스를 고속 유전체 데이터의 중앙 저장소와 분석 엔진으로 활용하면 데이터 이동 최소화, 자동화된 파이프라인 관리, 그리고 강력한 트랜잭션 보장을 얻을 수 있다. 다만, 입출력 병목, 메모리 관리, 스키마 진화 비용 등을 고려해 하이브리드 아키텍처(예: 파일 시스템과 DBMS 병행) 혹은 컬럼형/분산형 데이터베이스로의 전환이 필요할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기