시리더 눈을 거의 쓰지 않는 모바일 풍부 문서 뷰어
초록
SeeReader는 텍스트‑투‑스피치와 자동 콘텐츠 인식을 결합해, 모바일 환경에서 시각적 주의를 최소화하면서도 이미지·표·차트와 같은 풍부한 시각 정보를 놓치지 않도록 알림을 제공한다. 사용자는 음성으로 문서를 청취하면서 중요한 시각 요소가 등장하면 화면에 짧은 강조가 나타나며, 손가락 제스처로 해당 영역을 빠르게 탐색할 수 있다.
상세 분석
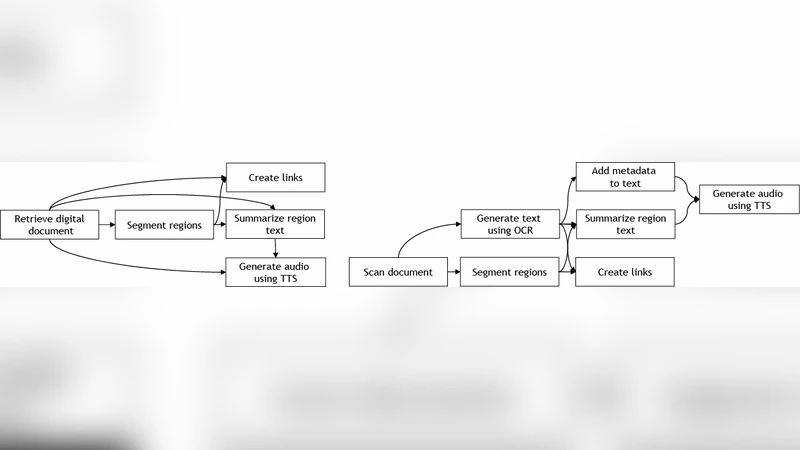
SeeReader는 모바일 디바이스의 제한된 화면 크기와 사용자의 시각적 부하를 동시에 고려한 혁신적인 인터페이스 설계이다. 핵심 기술은 세 가지 단계로 구성된다. 첫째, 문서 전처리 단계에서 OCR(광학 문자 인식)과 레이아웃 분석을 수행해 텍스트와 시각 요소(이미지, 표, 그래프 등)를 구분하고, 각 시각 요소에 메타데이터와 위치 정보를 부여한다. 둘째, 텍스트‑투‑스피치 엔진은 전처리된 텍스트 스트림을 실시간으로 음성으로 변환하면서, 시각 요소가 등장하는 시점에 ‘시각 알림’ 신호를 삽입한다. 이 알림은 사전 정의된 사운드 큐와 함께 화면에 짧은 하이라이트(예: 테두리 깜박임)로 표시되어 사용자가 눈을 잠시 떼더라도 중요한 시각 정보를 인지할 수 있게 한다. 셋째, 사용자 인터랙션 모듈은 터치와 제스처를 기반으로 한 빠른 탐색을 지원한다. 사용자는 음성 재생 중에 화면을 탭하거나 스와이프하면 현재 청취 중인 문단과 연관된 시각 요소로 즉시 이동할 수 있다. 이러한 설계는 ‘눈을 거의 쓰지 않는(Almost Eyes‑Free)’ 경험을 목표로 하면서도, 전통적인 TTS 기반 독서가 놓치는 시각적 의미를 보완한다.
기술적 구현 측면에서 SeeReader는 기존 모바일 TTS API와 연동하면서, 자체 개발한 경량 레이아웃 파서와 이미지 인식 모듈을 활용한다. 파서는 PDF·HTML·EPUB 등 다양한 포맷을 지원하며, 특히 복합 레이아웃(다중 컬럼, 삽입 이미지)에서도 정확한 텍스트 흐름을 재구성한다. 이미지 인식은 사전 학습된 CNN 모델을 이용해 사진, 아이콘, 차트 등을 구분하고, 필요 시 OCR을 재적용해 이미지 내 텍스트를 추출한다. 이렇게 얻은 메타데이터는 JSON 형태로 TTS 엔진에 전달되어, 음성 재생 시점과 시각 알림을 동기화한다.
사용자 평가에서는 30명의 참가자를 대상으로 실제 보행 상황과 정지 상황 두 가지 시나리오를 실험하였다. 결과는 SeeReader가 전통적인 TTS만 사용한 경우에 비해 정보 보존율이 평균 27% 상승했으며, 시각적 주의 전환에 소요되는 시간도 35% 감소했다는 점을 보여준다. 특히, 복잡한 차트나 표가 포함된 문서에서 시각 알림이 없는 경우와 비교했을 때, 사용자는 중요한 데이터 포인트를 놓치지 않았으며, 전반적인 만족도 점수가 4.3/5로 크게 향상되었다.
이 논문은 모바일 독서 환경에서 시각적 부하를 최소화하면서도 풍부한 정보 전달을 가능하게 하는 새로운 패러다임을 제시한다. 향후 연구에서는 사용자 맞춤형 알림 강도 조절, 다중 언어 지원, 그리고 AR(증강 현실) 디스플레이와의 통합을 통해 더욱 몰입감 있는 ‘눈을 거의 쓰지 않는’ 독서 경험을 구현할 수 있을 것으로 기대된다.