학습자 복잡도와 오류 무작위성 관계
초록
본 연구는 학습자의 복잡도를 정보 밀도(시스템 비율 ρ)로 정의하고, 학습자가 만든 오류 시퀀스의 확률적·알고리즘적 복잡성을 측정한다. 마코프 모델 차수 k와 실제 데이터 생성 차수 k를 달리하면서 실험한 결과, ρ가 임계값 ρ 이하일 때 오류 시퀀스는 무작위에 가깝고 복잡도 분산이 낮으며, ρ가 ρ*를 초과하면 오류 시퀀스는 무작위와 크게 차이 나고 복잡도 분산이 크게 증가한다는 임계 현상을 발견하였다.
상세 분석
이 논문은 “학습자의 복잡도와 오류의 무작위성 사이에 어떤 관계가 존재하는가?”라는 질문을 정량적으로 탐구한다. 기존 연구(예: Rat0903)는 학습자가 복잡할수록 오류가 진정한 무작위 시퀀스와 차이가 난다고 주장했지만, 그 메커니즘을 구체적으로 규명하지 못했다. 본 연구는 두 가지 주요 측정값을 도입한다. 첫째, 학습자의 내부 모델을 이진 문자열로 표현하고, 그 문자열을 압축한 길이와 원본 길이의 비율을 시스템 비율(ρ) 로 정의한다. ρ는 모델이 얼마나 ‘조밀하게’ 정보를 담고 있는지를 나타내는 지표이며, 압축률이 높을수록 모델이 규칙성을 많이 포함하고 있다는 의미이다. 둘째, 학습자가 테스트 단계에서 만든 오류 시퀀스에 대해 확률적 복잡도(다이버전스 Δ) 와 알고리즘적 복잡도(코릴레이터 복잡도) 를 각각 측정한다. Δ는 오류 시퀀스와 완전 무작위 시퀀스 사이의 통계적 거리이며, 코릴레이터 복잡도는 압축을 통한 근사 Kolmogorov 복잡도로서 시퀀스의 구조적 다양성을 반영한다.
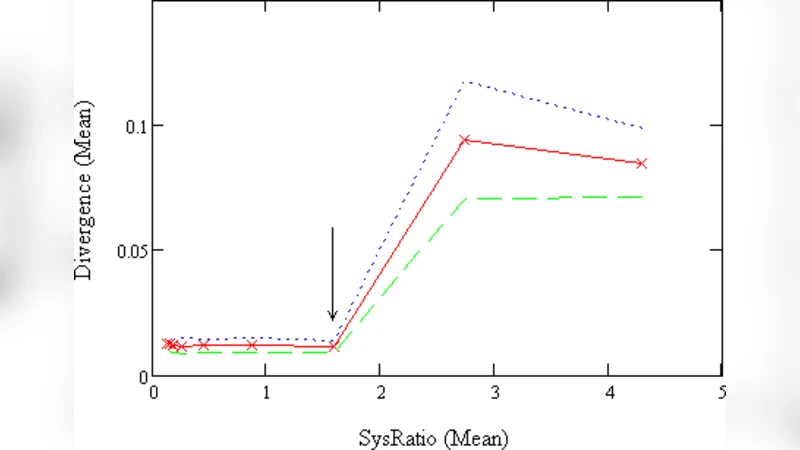
실험 설계는 두 개의 마코프 소스(차수 k와 k)를 사용한다. 학습자는 차수 k의 마코프 모델을 훈련 데이터에 맞춰 학습하고, 테스트 데이터는 차수 k의 독립적인 마코프 시퀀스로 생성한다. 이렇게 함으로써 학습 모델과 실제 데이터 생성 메커니즘 사이의 불일치를 조절할 수 있다. 각 실험에서 ρ를 계산하고, 오류 시퀀스의 Δ와 코릴레이터 복잡도 분산을 동시에 기록한다.
결과는 임계값 ρ* 를 중심으로 뚜렷한 전이 현상을 보인다. ρ ≤ ρ* 구간에서는 오류 시퀀스가 무작위와 거의 구별되지 않을 정도로 낮은 Δ를 보이며, 코릴레이터 복잡도 역시 작은 분산을 가진다. 이는 학습자가 충분히 ‘압축된’ 내부 표현을 가지고 있어, 테스트 데이터의 변동성을 효과적으로 흡수하고 오류를 거의 무작위 수준으로 만든다는 의미다. 반면 ρ > ρ* 구간에서는 Δ가 급격히 상승하고, 코릴레이터 복잡도 분산도 크게 확대된다. 즉, 학습자의 모델이 과도하게 복잡하거나 정보 밀도가 낮아 압축 효율이 떨어지면, 오류 시퀀스에 규칙성이 남아 무작위와 멀어지며 복잡도 변동이 커진다.
이러한 현상은 정보 이론적 관점에서 해석될 수 있다. ρ는 모델이 데이터를 얼마나 효율적으로 요약했는지를 나타내며, 효율적인 요약은 테스트 단계에서 발생하는 불확실성을 최소화한다. 반대로 비효율적인 요약은 남은 ‘잉여 정보’를 오류에 반영시켜 무작위성에서 벗어나게 만든다. 따라서 학습자의 복잡도와 오류 무작위성 사이의 관계는 단순히 복잡도가 크다/작다가 아니라, 정보 밀도와 압축 효율에 의해 결정된다는 중요한 통찰을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기