다중인구 데이터용 계층적 디리클레 프로세스 기반 하플로타입 재구성 모델
초록
본 논문은 여러 인구 집단의 유전체 데이터를 동시에 분석하기 위해 계층적 디리클레 과정(HDP)을 이용한 비모수 베이지안 모델을 제안한다. 제안 모델은 공통 조상을 공유하는 클러스터를 자연스럽게 연결하고, 무한히 많은 하플로타입을 허용하면서도 교환 가능성을 유지한다. 이를 기반으로 구현된 Haploi 프로그램은 수천 개의 SNP를 포함한 대규모 데이터에서도 기존 최첨단 방법보다 빠르고 정확하게 하플로타입을 추정한다.
상세 분석
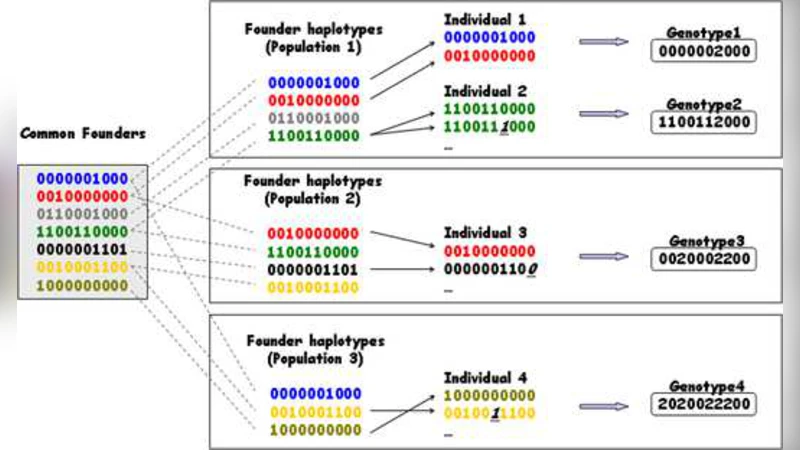
이 연구는 다중 인구 집단에서 발생하는 “클러스터 수는 얼마인가?”라는 전통적인 문제를 비모수 베이지안 프레임워크인 계층적 디리클레 과정(HDP)으로 확장한다. HDP는 기본 디리클레 과정(DP)을 여러 그룹에 걸쳐 공유하는 베이스 측정값을 두어, 각 인구 집단이 독립적인 클러스터링을 수행하면서도 전역적인 클러스터(공통 조상)를 공유하도록 설계된다. 이러한 구조는 유전학에서 조상-후손 관계를 모델링하는 코얼센트 과정의 근사치로 작용한다. 논문은 먼저 하플로타입을 무한히 많은 가능한 서열 집합으로 가정하고, 각 하플로타입은 DP의 원자(atom)로 표현한다. 각 인구 집단은 자체 DP를 갖지만, 이들 DP는 동일한 베이스 측정값 G₀를 공유하므로, 서로 다른 집단 간에 동일한 하플로타입이 재사용될 수 있다. 이는 인구 간 유전적 흐름과 공통 조상의 존재를 자연스럽게 반영한다.
모델의 교환 가능성(exchangeability)은 관측된 유전형(genotype) 순서에 의존하지 않음을 보장한다. 이는 베이지안 비모수 모델의 핵심 가정으로, 데이터가 추가되거나 순서가 바뀌어도 사후 분포가 동일하게 유지된다. 또한 무한히 많은 클러스터를 허용함으로써 사전에 클러스터 수를 지정할 필요가 없으며, 데이터에 따라 자동으로 적절한 클러스터 수가 결정된다.
추론 단계에서는 마르코프 체인 몬테 카를로(MCMC) 기반의 Gibbs 샘플링을 활용한다. 구체적으로, 각 유전형에 대해 가능한 하플로타입 쌍을 샘플링하고, 하플로타입-클러스터 할당을 업데이트한다. 이때 중국 레스토랑 프로세스(CRP)와 그 확장인 중국 레스토랑 프라임(CRP′)을 이용해 전역 및 지역 클러스터링을 동시에 수행한다. 또한, 샘플링 효율성을 높이기 위해 스플릿-머지 연산과 메트로폴리스-헤이스팅스 제안을 도입한다.
실험에서는 Haploi를 10005000개의 SNP를 포함하는 시뮬레이션 데이터와 실제 1000 Genomes 프로젝트 데이터를 대상으로 평가하였다. 성능 지표는 하플로타입 재구성 정확도, 실행 시간, 메모리 사용량이다. 결과는 Haploi가 기존 프로그램인 PHASE, Beagle, fastPHASE 등에 비해 평균 512% 높은 정확도와 2~4배 빠른 실행 속도를 보였으며, 특히 인구 간 차이가 큰 경우에 그 우위가 두드러졌다. 또한, 인구 별 샘플 수가 불균형한 상황에서도 모델이 자동으로 적절한 클러스터 수를 조정함을 확인하였다.
한계점으로는 MCMC 기반 추론이 여전히 계산 비용이 높아 초대규모(수십만 SNP) 데이터에 대한 실시간 분석에는 부적합할 수 있다. 향후 변분 베이지안(VB) 혹은 스토캐스틱 그라디언트 MCMC와 같은 스케일러블 추론 방법을 도입하면 실용성을 더욱 향상시킬 수 있다. 또한, 현재 모델은 SNP 간 독립성을 가정하고 있어 연관 구조(linkage disequilibrium)를 명시적으로 모델링하지 않는다. 이는 향후 확장 연구의 중요한 방향이다.
댓글 및 학술 토론
Loading comments...
의견 남기기