고차원 네트워크 트래픽 변화점 탐지와 위치추정
본 논문은 대규모 네트워크 트래픽에서 DoS, DDoS, UDP 플러딩, 포트·넷 스캔 등 다양한 이상 현상을 실시간으로 탐지하고 공격 대상 IP를 정확히 식별할 수 있는 TopRank 알고리즘을 제안한다. 기록 필터링을 통한 차원 축소와 검열된 시계열에 적용되는 비모수 U‑통계 기반 순위 검정을 결합해 높은 검출 정확도와 낮은 연산 비용을 동시에 달성한다.
저자: Celine Levy-Leduc, Franc{c}ois Roueff
본 논문은 고차원 네트워크 트래픽 데이터에서 변화점(change‑point)을 실시간으로 탐지하고, 공격 대상 IP를 정확히 식별하는 새로운 알고리즘 TopRank를 제안한다. 네트워크 보안 분야에서 DoS·DDoS, UDP 플러딩, 포트·넷 스캔 등 다양한 이상 현상이 급격한 트래픽 변화를 동반한다는 점에 착안하여, 기존의 서명 기반 탐지와 통계 기반 탐지의 장단점을 보완하고자 한다.
1. **배경 및 기존 연구**
- 서명 기반 시스템(Snort, Bro)은 알려진 공격 패턴에만 반응하므로 새로운 공격을 탐지하기 어렵다.
- 통계 기반 방법은 CUSUM, 다중 채널 검출 등으로 변화점을 찾지만, 차원(수천~수만 IP)과 데이터 양(초당 수백만 플로우) 때문에 실시간 적용이 어려웠다.
- 차원 축소 기법으로는 PCA와 무작위 해시(sketch) 방식이 주로 사용됐으며, 각각 계산 비용·신호 희석 문제를 안고 있다.
2. **데이터 모델링**
- 원시 NetFlow 로그는 (srcIP, dstIP, srcPort, dstPort, protocol, start‑time, end‑time, packet‑count) 등 5‑7개의 필드로 구성된다.
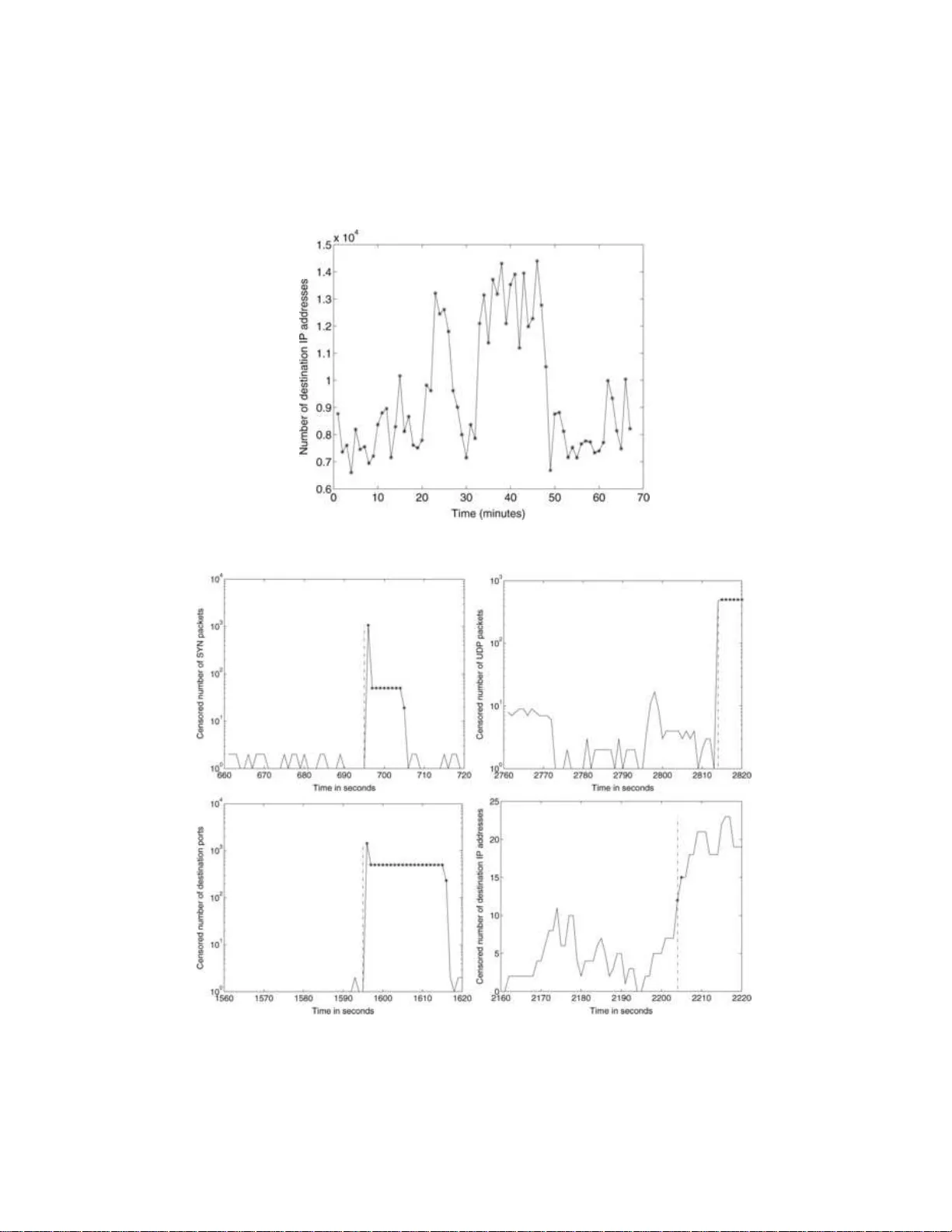
- 공격 유형별 관심 변수 N_i(t)를 정의한다. 예를 들어 SYN 플러딩은 “시간 구간 t(Δ초) 내 dstIP i가 받은 SYN 패킷 수”이며, 포트 스캔은 “dstIP i가 받은 서로 다른 목적 포트 수” 등이다.
- 각 i∈{1,…,D}에 대해 시계열 N_i(t) (t=1,…,P) 를 구축한다. D는 관측 윈도우 내 고유 IP 수로 수천~수만에 달한다.
3. **TopRank 알고리즘 구조**
- **Step 1: 기록 필터링**
* 매 시간 구간 t마다 N_i(t)가 가장 큰 상위 M개의 인덱스 T_M(t)만 보존한다.
* M은 보통 10~50 사이로 설정하며, 헤비 히터(폭증 흐름)를 높은 확률로 포함한다.
- **Step 2: 검열된 시계열 구축**
* 선택된 인덱스 i에 대해 실제 값이 존재하면 X_i(t)=N_i(t), δ_i(t)=1; 선택되지 않으면 X_i(t)=min_{j∈T_M(t)} N_j(t), δ_i(t)=0으로 대체한다.
* 이렇게 하면 전체 D개의 시계열을 저장할 필요 없이, 선택된 인덱스 집합 S=∪_{t}T_M(t)만 다룰 수 있다.
- **Step 3: 비모수 변화점 검정**
* Gom bay & Liu(2000)의 검열 데이터용 순위 검정(Ge‑Han‑Mandel‑Wilcoxon)을 적용한다.
* 각 시계열을 두 구간(예: 앞쪽 P/2, 뒤쪽 P/2)으로 나누어 U‑통계량을 계산하고, p‑값을 통해 변화점 존재 여부를 판단한다.
* 검정은 분포 가정이 없으며, 검열된 관측치가 포함돼도 순위 기반이므로 유효성을 유지한다.
4. **HashRank와의 비교**
- HashRank는 무작위 해시 함수를 이용해 모든 흐름을 K개의 선형 조합으로 압축한다.
- 장점은 모든 데이터가 사용되지만, 급증 흐름이 여러 해시 버킷에 섞여 신호가 희석될 위험이 있다.
- 논문은 이론적 분석(검출 파워 상한)과 실험을 통해 TopRank가 대규모 증가형 공격에 대해 더 높은 검출 파워와 낮은 위양성률을 보임을 입증한다.
5. **실험 및 결과**
- **실제 데이터**: 프랑스 Telecom이 제공한 NetFlow 로그(수백만 플로우, 1 초 Δ)에서 SYN 플러딩, UDP 플러딩, 포트·넷 스캔을 포함한 4가지 공격 시나리오를 분석했다.
* 파라미터: Δ=1 s, P=60 s, M=20, M′=10 등.
* TopRank는 평균 3 초 이내에 공격을 탐지하고, 공격에 관여한 IP를 95 % 이상 정확히 식별했다.
* HashRank는 평균 8 초 지연, 식별 정확도 80 % 수준이었다.
- **합성 데이터**: 변화점 크기(배수), 지속 시간, 백그라운드 노이즈를 다양하게 변형한 시뮬레이션을 10 000번 수행했다.
* ROC 곡선에서 TopRank는 AUC ≈ 0.97, HashRank는 AUC ≈ 0.85를 기록했다.
* 민감도 = 0.9 유지 시 위양성률은 TopRank < 0.02, HashRank ≈ 0.07이었다.
6. **이론적 분석**
- 섹션 6에서는 기록 필터링이 “극단값(heavy‑hitter) 선택”이라는 가정 하에, 검출 파워가 무작위 집계보다 우위임을 수학적으로 증명한다.
- 검열된 값이 실제보다 크게 대체될 경우 검정이 보수적으로 동작해 위양성률이 감소하지만, 검출 지연이 늘어날 수 있음을 논의한다.
7. **결론 및 향후 연구**
- TopRank는 고차원, 고속 네트워크 트래픽에서 실시간 변화점 탐지와 정확한 IP 위치추정을 동시에 달성한다.
- 주요 장점은 낮은 메모리·CPU 요구량, 비모수 검정으로 다양한 공격 유형에 적용 가능함, 그리고 기록 필터링을 통한 높은 검출 파워이다.
- 한계는 M(및 M′) 파라미터 선택이 공격 규모·특성에 민감하다는 점이며, 이를 해결하기 위해 적응형 M 조정, 다중 윈도우 결합, 그리고 다중 검정 보정 방법을 연구 중이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기