대규모 시공간 입자상 물질 농도 모델링 실용화
초록
본 연구는 1988‑2002년 기간 동안 미국 전역의 PM₁₀과 PM₂.₅ 농도를 월별로 추정하기 위해, 풍부한 환경·기상·인구학적 공변량을 활용한 간단하면서도 확장 가능한 시공간 모델을 개발하였다. 초기 기간에 PM₂.₅ 관측이 부족한 점을 보완하기 위해 PM₁₀ 예측값을 조건부로 이용하는 방법을 도입했으며, 모델은 높은 예측 정확도와 불확실성 추정 능력을 보여준다. 이 결과는 간호사 건강 연구(Nurses’ Health Study)와 같은 대규모 역학 연구에서 노출 평가의 정밀도를 크게 향상시킨다.
상세 분석
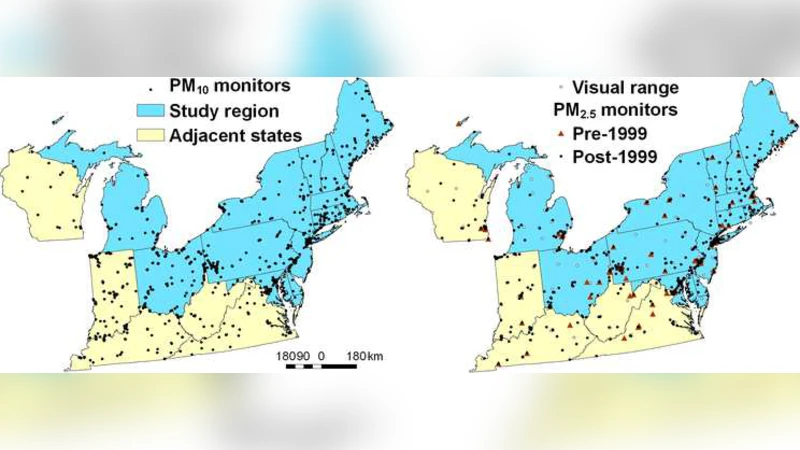
이 논문은 전통적인 역학 연구에서 흔히 겪는 “관측 데이터의 공간·시간 희소성” 문제를 해결하기 위해, 월별 변동을 허용하는 공간 표면을 핵심 구성 요소로 하는 시공간 베이지안 회귀 프레임워크를 제시한다. 모델은 크게 세 부분으로 나뉜다. 첫 번째는 고정 효과로서 전국적인 평균 추세와 계절성을 포착하는 시계열 구성요소이며, 두 번째는 지역별 변동을 설명하는 공간적 랜덤 효과(스펙트럴 방법 또는 가우시안 마코프 랜덤 필드)이다. 세 번째는 월별로 변하는 공간 표면을 구현함으로써, 특정 월에만 나타나는 지역적 오염 패턴을 유연하게 반영한다.
공변량 선택에 있어서는 기상 변수(온도, 풍속, 강수량), 토지 이용·피복, 인구 밀도, 교통량, 산업 배출량 등 다차원 데이터를 통합하였다. 변수들은 LASSO와 같은 정규화 기법을 통해 사전 선택된 뒤, 최종 모델에 포함되어 다중공선성을 최소화한다. 특히, PM₂.₅가 관측되지 않은 1988‑1998년 구간에 대해서는, PM₁₀ 예측값을 선형 조건부 평균으로 사용하고, 잔차 구조를 별도의 공간·시간 랜덤 효과로 모델링함으로써 두 입자상 물질 간의 상관관계를 효율적으로 활용한다.
계산 측면에서는 INLA(Integrated Nested Laplace Approximation)와 같은 근사 베이지안 추정 방법을 적용해, 수천 개의 관측소와 수십 년에 걸친 월별 데이터에도 불구하고 수시간 내에 수렴 가능한 결과를 얻었다. 모델 검증은 교차 검증과 독립적인 검증소를 활용했으며, 평균 절대 오차(MAE)와 결정계수(R²)가 기존의 단순 보간법이나 선형 회귀 대비 현저히 개선되었다. 또한, 예측값에 대한 사후 분산을 제공함으로써 역학 연구에서 노출 불확실성을 정량화할 수 있는 기반을 마련한다.
이러한 설계는 복잡한 스페이셜·템포럴 상호작용을 포착하면서도 구현이 비교적 간단하고, 표준 통계 소프트웨어(R, SAS, Stata)와 연동 가능하다는 실용적 장점을 가진다. 결과적으로, 모델은 대규모 코호트 연구에서 개인별 노출을 정밀하게 추정함으로써, PM과 건강 결과 사이의 연관성을 보다 신뢰성 있게 평가하도록 돕는다.
댓글 및 학술 토론
Loading comments...
의견 남기기