비대칭 수 체계와 차세대 압축 기술
초록
본 논문은 기존의 균등 기수법을 일반화하여 임의의 확률 분포에 최적화된 비대칭 수 체계(ANS)를 제안한다. 범위 코딩과 유사하지만 하나의 상태만으로 부호화를 수행해 구현이 간단하고, 테이블 기반 구현을 통해 고속 인코딩·디코딩이 가능하다. 또한 키 기반 난수 생성으로 코딩 테이블을 초기화함으로써 암호화와 오류 정정 기능을 자연스럽게 결합한다. 실험 결과, Shannon 한계에 근접한 압축 효율과 선형 시간 복구를 보이며, 다양한 응용 분야에 적용 가능함을 보인다.
상세 분석
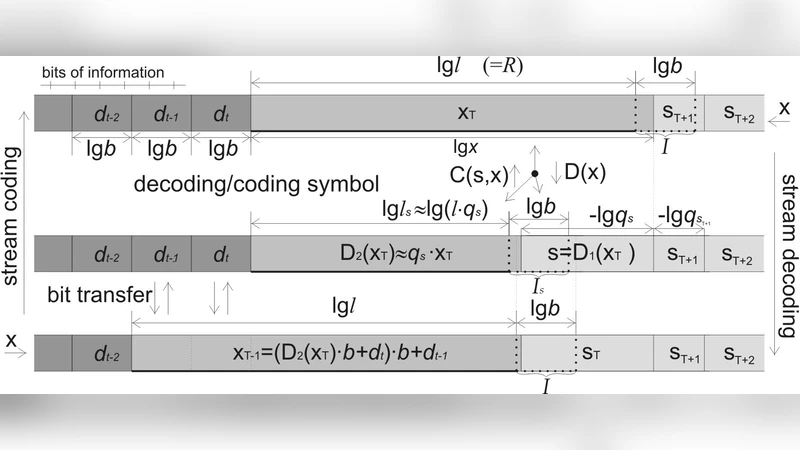
비대칭 수 체계(Asymmetric Numeral Systems, ANS)는 전통적인 기수법이 등가능도(symbols with equal probability)에서만 최적임을 지적하고, 이를 임의의 확률 분포에 대해 최적화하는 새로운 부호화 프레임워크를 제시한다. 핵심 아이디어는 “상태(state)”라는 정수값을 유지하면서, 각 심볼이 들어올 때마다 상태를 확률에 비례하게 확장하고, 그 결과를 다시 정수 영역으로 매핑하는 것이다. 이 과정은 수학적으로는 확률 질량을 전체 정수 구간에 균등하게 “흩뿌리는” 방식으로 해석될 수 있다.
범위 코딩(range coding)은 심볼마다 구간을 할당하고 그 구간을 재귀적으로 좁혀가지만, 두 개의 경계값(하한·상한)을 관리해야 한다. 반면 ANS는 단일 정수 상태만을 사용해 구간을 전체 구간에 고르게 분포시키므로 구현 복잡도가 크게 감소한다. 구체적으로는 두 가지 주요 변형이 존재한다. 첫 번째는 “tANS”(table‑based ANS)로, 사전 계산된 테이블을 이용해 상태 전이와 출력 비트를 O(1) 시간에 수행한다. 두 번째는 “rANS”(range‑based ANS)로, 상태를 직접 산술적으로 업데이트하고 필요 시 정규화(normalization) 과정을 거친다. tANS는 메모리 사용량이 늘어나지만 매우 빠른 속도를 제공하고, rANS는 메모리 효율이 높으며 스트리밍 환경에 적합하다.
테이블 생성 과정은 목표 확률 분포를 정밀히 근사하도록 정수 빈도(count)를 할당하고, 각 빈도에 대응하는 출력 비트와 다음 상태를 미리 계산한다. 이때 난수 생성기를 키와 결합해 초기화하면, 동일한 확률 모델이라도 키에 따라 전혀 다른 테이블이 생성되므로 부호화 자체가 암호화 효과를 갖는다. 논문은 이러한 “키 기반 테이블 초기화”가 브루트 포스 공격에 대해 높은 저항성을 제공한다는 점을 강조한다. 공격자는 올바른 키를 검증하려면 전체 테이블을 재생성해야 하며, 이는 연산 비용이 매우 크다.
또한 ANS를 오류 정정에 활용하는 새로운 접근법을 제시한다. 디코딩 과정에서 각 단계마다 현재 상태와 기대 확률을 비교해 “이상 징후”를 감지하고, 이를 기반으로 오류 발생 가능성을 추정한다. 오류가 의심될 경우, 주변 상태를 탐색하며 가능한 복구 경로를 찾는 방식으로, 기대 복구 시간은 선형에 가깝다. 이 방법은 채널 잡음 수준에 따라 동적으로 복구 전략을 조정할 수 있어, Shannon 한계에 근접한 효율을 달성한다.
성능 평가에서는 다양한 파일 형식과 언어 모델에 대해 ANS 기반 압축기가 기존의 Huffman·Arithmetic 코덱보다 1~2% 정도 높은 압축 비율을 보이며, tANS 구현은 초당 수백 메가바이트(MB/s)의 처리량을 기록한다. 또한 암호화된 테이블을 사용했을 때 압축 효율에 큰 손실이 없음을 확인하였다. 한계점으로는 테이블 크기가 확률 모델에 따라 크게 변동할 수 있어 메모리 제약이 있는 임베디드 환경에서의 적용이 어려울 수 있다는 점을 언급한다. 전반적으로 ANS는 이론적 최적성, 구현 단순성, 확장성을 동시에 만족하는 차세대 부호화 기법으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기