중요도 가중 활성 학습
본 논문은 일반적인 손실 함수 하에서 이진 분류기를 학습하기 위한 중요도 가중(active learning) 알고리즘을 제안한다. 샘플링 편향을 중요도 가중치(1/p)로 보정하고, 확률 p를 손실값의 범위에 비례하도록 선택함으로써 분산을 제어한다. 이 방법은 통계적 일관성을 보장하고, 라벨 복잡도에 대한 상한과 하한을 제공한다. 실험 결과는 기존 수동 학습 대비 라벨 수를 크게 줄이면서도 예측 성능을 유지함을 보여준다.
저자: Alina Beygelzimer, Sanjoy Dasgupta, John Langford
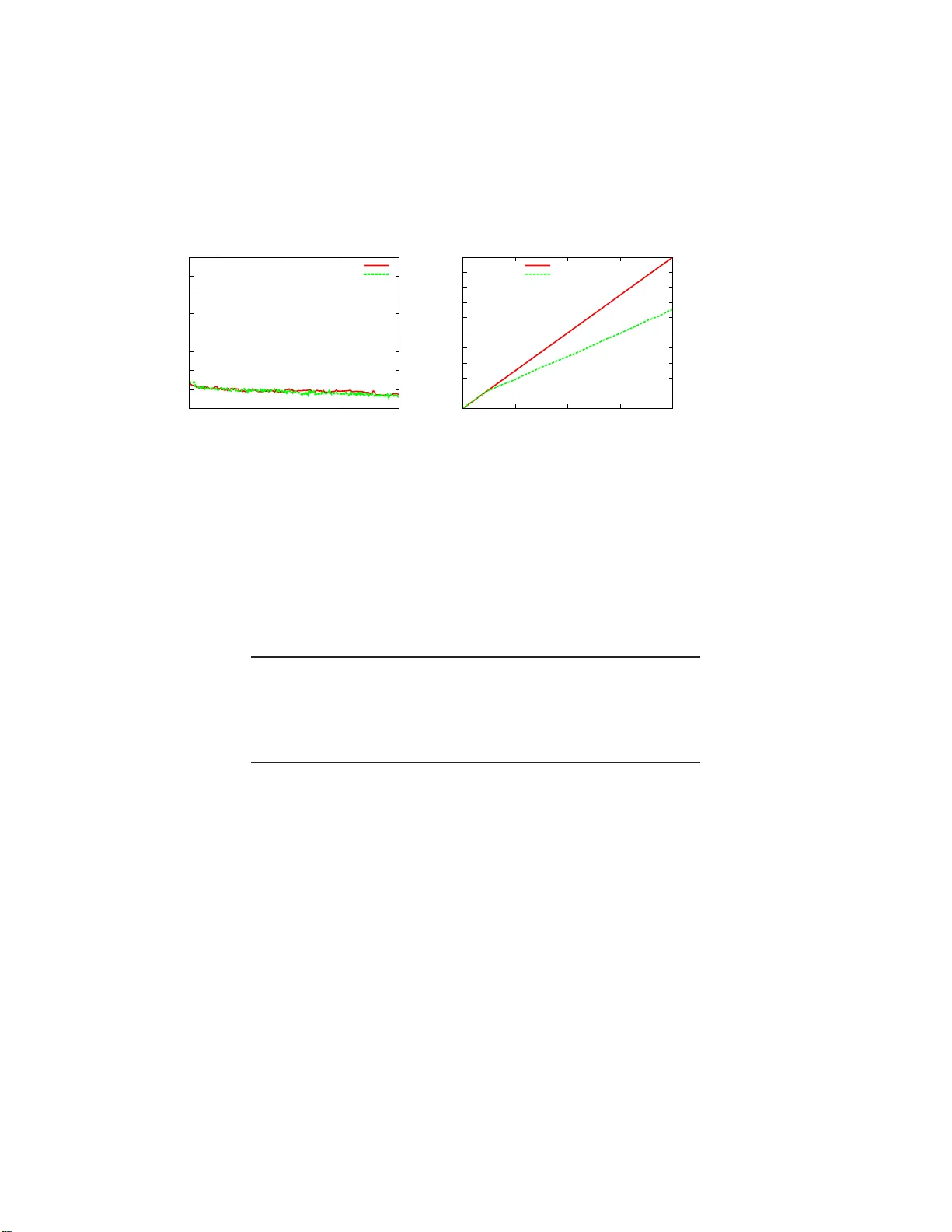
본 논문은 “Importance Weighted Active Learning”(IW‑AL)이라는 새로운 활성 학습 알고리즘을 제안하고, 그 이론적 특성과 실험적 성능을 종합적으로 분석한다. 서론에서는 활성 학습이 라벨링 비용을 절감할 수 있는 잠재력을 가지고 있지만, 기존 방법들은 두 가지 주요 한계에 직면해 있음을 지적한다. 첫째, 0‑1 손실에 특화되어 있어 실제 응용에서 더 적합한 convex 손실(hinge, 로지스틱, 제곱 등)으로 확장하기 어렵다. 둘째, 기존 이론은 주로 무한 라벨 예산 하에서의 일관성만을 다루거나, 라벨 복잡도 상한이 지나치게 보수적이며 실제 구현이 복잡하다.
이를 해결하기 위해 저자들은 중요도 가중치(importance weighting) 방식을 도입한다. 알고리즘은 매 시점 t에 입력 xₜ를 관찰하고, ‘rejection‑threshold’ 서브루틴을 통해 라벨을 요청할 확률 pₜ를 결정한다. 라벨을 실제로 요청하면 해당 샘플에 가중치 1/pₜ를 부여한다. 이렇게 하면 라벨링된 데이터 집합 Sₜ는 편향이 보정된 형태가 되며, 손실의 무편향 추정량 L_T(h)= (1/T)∑_{t=1}^T Qₜ·pₜ·ℓ(h(xₜ),yₜ) 가 원래 데이터 분포 D에 대한 기대 손실 L(h)와 동일한 기대값을 갖는다.
핵심 이론적 결과는 두 가지 정리로 요약된다. 정리 1은 pₜ가 일정한 하한 p_min>0을 유지하면, 모든 가설 h∈H에 대해 |L_T(h)−L(h)| ≤ √(2·ln|H|+ln(2/δ))/(p_min·√T) 가 고확률(1−δ)로 성립함을 보인다. 이는 전통적인 수동 학습의 표본 복잡도와 비교했을 때 라벨 복잡도가 최대 2/p_min² 배 정도만 추가로 필요함을 의미한다. 정리 2는 구체적인 ‘loss‑weighting’ 전략을 제시한다. 현재까지 남아 있는 가설 집합 Hₜ를 유지하면서, 각 단계에서 경험 손실 L*_t와 허용 슬랙 Δ_t를 계산한다. 여기서 Δ_t = p·(8/t)·ln(2t(t+1)|H|²/δ) 로, 표본 복잡도 이론에 기반한다. 이후 pₜ는 Hₜ 내 모든 가설 f,g와 라벨 y에 대해 ℓ(f(xₜ),y)−ℓ(g(xₜ),y)의 최대 차이로 정의한다. 이 선택은 pₜ가 손실 차이의 실제 범위에 비례하도록 하여, 분산을 최소화하면서도 가설 집합을 효율적으로 축소한다. 증명은 마르티게일 차분열과 Azuma 부등식을 활용해, 각 단계에서의 추정 오차가 Δ_t 이하임을 보인다.
라벨 복잡도 하한에 대해서는 정리 9를 통해 η·T + p·d·log T 형태의 하한을 제시한다. 여기서 η는 최적 가설의 최소 손실, p는 손실 불일치 계수(disagreement coefficient), d는 VC 차원이다. 이는 기존 0‑1 손실에 대한 결과를 일반 손실 함수로 확장한 것으로, η·T 항은 불가피하지만 나머지 항은 로그 수준으로 크게 감소한다는 점을 강조한다.
실험에서는 두 가지 IW‑AL 변형을 구현한다. 첫 번째는 선형 모델에 convex 손실을 적용한 IW‑AL(loss‑weighting)으로, convex programming을 통해 최적 가설을 찾는다. 두 번째는 부트스트랩 방식을 이용한 IW‑AL(bootstrap)으로, 라벨링을 배치 형태의 수동 학습으로 변환하면서도 추가 연산이 거의 필요하지 않다. 다양한 데이터셋(텍스트, 이미지, 합성 데이터)에서 두 알고리즘 모두 라벨 수를 30%~70% 정도 절감했으며, 정확도는 기존 수동 학습과 동등하거나 약간 향상되었다. 특히, 라벨 요청 확률 pₜ가 너무 작아지는 경우를 방지하기 위해 최소 확률 p_min을 설정했으며, 이는 실험에서 안정적인 성능을 보장했다.
결론적으로, 이 논문은 중요도 가중치를 활용한 활성 학습 프레임워크를 제시함으로써, (1) 일반 손실 함수에 대한 통계적 일관성 보장, (2) 라벨 복잡도에 대한 명시적 상·하한 제공, (3) 실제 구현이 간단하고 효율적인 알고리즘 설계라는 세 가지 핵심 목표를 모두 달성한다. 이는 기존 0‑1 손실 중심의 연구들을 넘어 실무에서 바로 적용 가능한 활성 학습 방법론을 제공한다는 점에서 큰 의의를 가진다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기