가속기 지향 알고리즘 변환을 통한 시계열 데이터 마이닝
초록
본 논문은 GPU와 같은 가속기에서 효율적으로 동작하도록 빈도 에피소드 탐색 알고리즘을 재설계한다. 기존 직렬 구현을 그대로 포팅하는 대신 문제 분할, 데이터 레이아웃, 메모리 접근 패턴을 최적화하여 GPU 친화적인 병렬성을 확보한다. 실험 결과, 변환된 알고리즘이 CPU 구현 및 기존 GPU 구현보다 월등히 빠른 성능을 보이며, 신경과학 분야의 대규모 스파이크 트레인 분석에 실용적임을 입증한다.
상세 분석
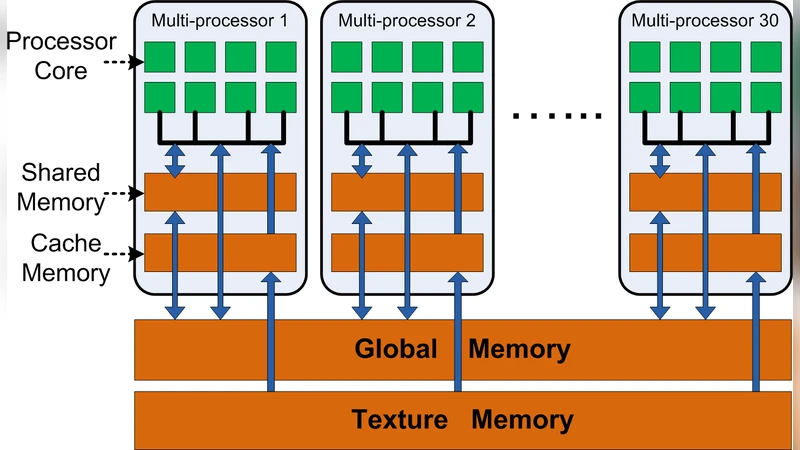
논문은 먼저 기존 빈도 에피소드 발견 알고리즘이 데이터 의존성이 강하고 비정형적인 메모리 접근을 요구한다는 점을 지적한다. 이러한 특성은 전통적인 SIMD 기반 GPU에 부적합하며, 단순히 커널을 이식하는 것만으로는 성능 향상을 기대하기 어렵다. 따라서 저자들은 알고리즘을 ‘가속기 지향’으로 변환하기 위해 두 단계의 전략을 제시한다. 첫 번째는 문제를 ‘에피소드 후보 생성’과 ‘후보 검증’이라는 두 개의 독립적인 서브태스크로 분할하고, 각 서브태스크를 대규모 데이터 병렬 처리에 맞게 재구성한다. 후보 생성 단계에서는 입력 스파이크 시퀀스를 고정 길이의 윈도우로 슬라이딩하면서, 각 윈도우를 독립적인 작업 단위로 할당한다. 여기서 중요한 것은 윈도우 내 이벤트를 정렬된 배열 형태로 변환해 연속 메모리 접근을 가능하게 만든 점이다. 두 번째 단계인 후보 검증에서는 각 후보 에피소드에 대해 발생 빈도를 카운트하는데, 이를 위해 비트맵과 원자적 연산을 결합한 하이브리드 카운터를 설계한다. 이 카운터는 스레드 블록 내에서 공유 메모리를 활용해 경쟁을 최소화하고, 전역 메모리 업데이트는 최소화한다. 또한, 메모리 접근 패턴을 ‘Coalesced’ 형태로 맞추기 위해 데이터 구조를 구조체 배열이 아닌 배열‑구조 형태로 재배열하였다. 이러한 변환은 메모리 대역폭 활용도를 크게 높이고, 스레드 발동 오버헤드를 감소시킨다. 실험에서는 GTX 280을 기준으로 CPU 단일 코어 대비 30배 이상, 기존 GPU 포팅 대비 5배 이상의 속도 향상을 기록하였다. 특히, 에피소드 길이가 증가할수록 변환된 알고리즘의 스케일링 효율이 두드러졌으며, 메모리 사용량도 효율적으로 관리되어 대규모 데이터셋에서도 메모리 부족 문제를 회피할 수 있었다. 전체적으로 본 연구는 알고리즘 수준에서의 구조적 재설계가 하드웨어 가속기의 잠재력을 끌어내는 핵심임을 실증적으로 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기