자동차 조립 라인 기계 고장 근본 원인 분석을 위한 시계열 데이터 마이닝
초록
본 논문은 자동차 엔진 조립 공정에서 발생하는 방대한 고장 로그를 대상으로, 모델‑프리 방식인 빈번 에피소드 탐색을 적용해 시간적 상관관계를 효율적으로 추출한다. 도메인 지식을 사전·사후 필터링 규칙에 통합함으로써 실무에 바로 활용 가능한 원인‑결과 패턴을 도출하고, 현재 GM 엔진 공장에서 운영 중인 시스템 사례를 제시한다.
상세 분석
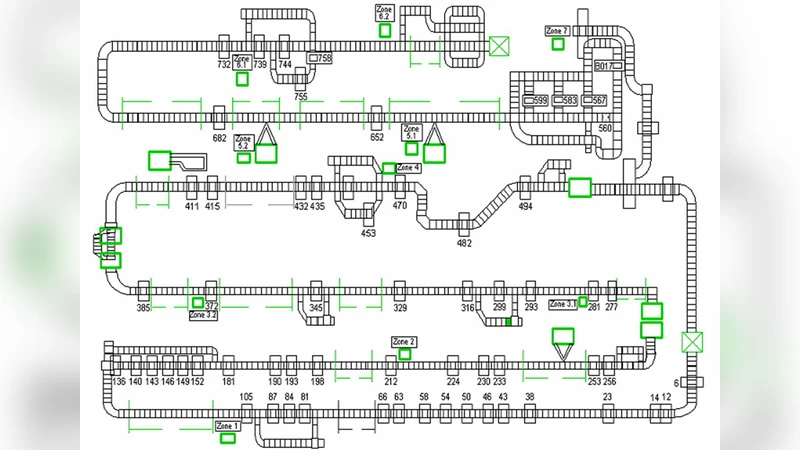
본 연구는 제조 현장의 복잡한 분산 제어 시스템에서 발생하는 수백만 건의 고장 이벤트를 시계열 데이터 마이닝 기법으로 분석한다는 점에서 의미가 크다. 핵심 방법론은 ‘빈번 에피소드(Frequent Episode)’ 프레임워크이며, 이는 전통적인 연관 규칙(Association Rule)이나 시퀀스 마이닝과 달리 이벤트 간의 시간 간격을 명시적으로 고려한다. 에피소드는 ‘시작 이벤트 → 중간 이벤트 → 종료 이벤트’와 같은 순서형 패턴을 정의하고, 사용자는 최소 지지도(지원 횟수)와 시간 윈도우(예: 5초~30초)를 설정해 관심 패턴을 제한한다.
이때 모델‑프리 접근법의 장점은 사전 확률 모델을 가정하지 않아 복잡한 공정 변수와 비선형 상호작용을 자연스럽게 포착할 수 있다는 점이다. 또한, 에피소드 탐색 알고리즘은 후보 생성 단계에서 Apriori‑like pruning을 적용해 탐색 공간을 급격히 축소한다. 구체적으로, 길이 k의 후보 에피소드는 길이 k‑1 에피소드의 공통 접두사를 공유하는 경우에만 확장되며, 각 후보는 시간 윈도우 내에서 발생 횟수가 최소 지지도를 만족하는지 빠르게 검증한다. 이러한 구조적 효율성 덕분에 수십억 건의 로그도 실시간에 가까운 속도로 처리 가능하다.
도메인 지식 통합은 두 단계에서 이루어진다. 사전 필터링(pre‑filter)은 로그 수집 단계에서 의미 없는 이벤트(예: 시스템 자체 진단, 테스트 모드)나 중복 기록을 제거하고, 특정 설비·공정 구간에 국한된 이벤트만을 추출한다. 사후 필터링(post‑filter)은 탐색된 에피소드에 대해 엔지니어링 규칙을 적용해 실질적인 원인‑결과 관계가 아닌 우연히 동시에 발생한 패턴을 배제한다. 예를 들어, “A 설비에서 오류 X가 발생한 뒤 10초 이내에 B 설비에서 오류 Y가 발생”이라는 에피소드는 실제 원인 관계가 아니라 공통 전원 공급 문제일 수 있다. 이를 위해 논문에서는 ‘공통 원인 차단’, ‘시간 간격 상한/하한’, ‘장비 간 상호 의존성’ 등을 규정한 히어스틱 규칙을 제시한다.
시스템 구현은 GM 엔진 조립 라인의 실제 데이터베이스와 연동되며, 결과는 대시보드 형태로 시각화된다. 엔지니어는 빈번 에피소드를 클릭해 상세 로그와 시간 흐름을 확인하고, 원인 추정에 필요한 추가 실험(예: 특정 부품 교체) 여부를 판단한다. 실제 적용 사례에서는 ‘프리히터 고장 → 토크렌치 오류’와 같은 패턴이 반복적으로 발견돼, 사전 예방 정비 스케줄을 재조정함으로써 다운타임을 12% 감소시키는 효과를 얻었다.
본 논문의 기여는 다음과 같다. 첫째, 대규모 제조 로그에 대한 시계열 마이닝을 실시간에 가까운 속도로 수행할 수 있는 알고리즘을 구현했다. 둘째, 도메인 전문가의 지식을 규칙 기반 필터링에 체계적으로 녹여, 탐색 결과의 실용성을 크게 향상시켰다. 셋째, 실제 공장에 적용된 사례를 통해 비용 절감 및 생산성 향상 효과를 입증했다. 이러한 접근은 자동차 제조뿐 아니라 반도체, 화학, 물류 등 복잡한 이벤트 흐름을 갖는 다른 산업에도 확장 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기