생존곡선을 이용한 서열형 질적 데이터 비교 방법
초록
본 논문은 서열형 질적 변수를 비교할 때 전통적인 비모수 검정 대신 생존분석(생존곡선)을 적용하는 새로운 접근법을 제안한다. 두 개의 임상 사례(만성 C형 간염 치료제 시험과 만성 중이염 환자의 미각 변화)에서 이 방법을 적용하여, 첫 번째 사례에서는 치료군 간 차이가 없음을(p > 0.5), 두 번째 사례에서는 유의한 차이(p < 0.05)를 확인하였다. 결과적으로 생존곡선 기반 분석이 임상 연구자에게 친숙하면서도 효과적인 대안이 될 수 있음을 시사한다.
상세 분석
이 연구는 서열형(ordinal) 질적 데이터의 비교에 있어 기존에 많이 사용되는 Mann‑Whitney U, Kruskal‑Wallis, Cochran‑Armitage trend test 등 비모수 검정이 갖는 해석상의 어려움과 가정 위반 가능성을 지적한다. 특히 임상 현장에서 “생존곡선”이라는 용어와 그래프는 이미 약물 효능·안전성 평가에 널리 쓰이고 있어, 연구자들이 직관적으로 결과를 이해하고 발표할 수 있다는 점이 큰 장점이다.
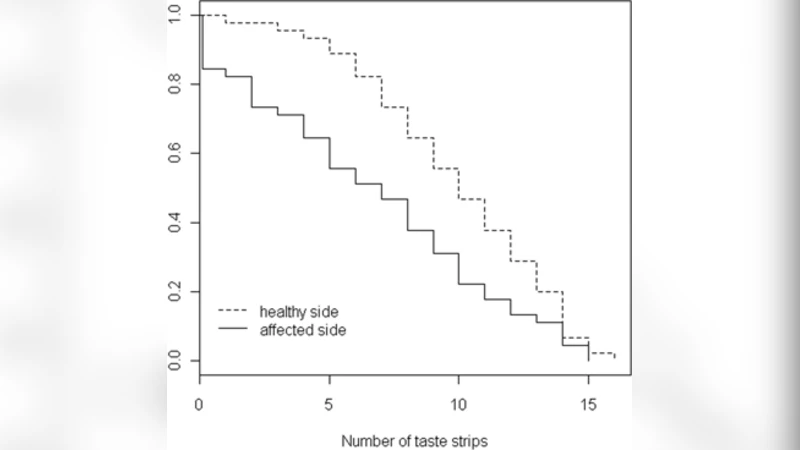
방법론적으로 저자는 기존의 “survival‑agreement plot”을 변형하여, 각 서열 수준을 ‘시간’에 대응시키고 사건 발생(예: 특정 등급 도달) 여부를 ‘생존/소멸’로 정의한다. 이후 Kaplan‑Meier 추정량을 구하고, 두 그룹 간 차이는 log‑rank 검정 혹은 Wilcoxon‑Breslow‑Gehan 검정을 통해 평가한다. 이러한 접근은 데이터가 검열(censoring)될 경우에도 자연스럽게 처리할 수 있다는 추가적인 이점을 제공한다.
첫 번째 사례에서는 silymarin/metionin 복합제가 위약과 비교했을 때 ALT, AST 등 효소 수치와 증상 점수에서 차이가 없었으며, 생존곡선 역시 겹치는 형태를 보였다. p값이 0.5 이상으로 나타난 점은 기존 비모수 검정과 동일한 결론을 뒷받침한다. 두 번째 사례에서는 건강한 측면과 병변 측면의 미각 점수 차이를 생존곡선으로 시각화했을 때, 명확한 분리와 함께 p < 0.05의 유의성을 보였다. 이는 기존에 사용되던 χ² 검정보다 그래프를 통한 직관적 해석이 용이함을 보여준다.
하지만 몇 가지 한계도 존재한다. 서열형 데이터가 실제 ‘시간’ 개념과 연관이 없기 때문에, 인위적으로 시간축을 설정하는 과정에서 해석상의 혼동이 발생할 수 있다. 또한, 사건 발생률이 매우 낮거나 높은 경우 Kaplan‑Meier 곡선이 급격히 평탄해져 차이를 감지하기 어려워질 위험이 있다. 마지막으로, log‑rank 검정은 위험비가 일정하다는 가정을 전제로 하는데, 서열형 데이터에서는 이 가정이 반드시 성립하지 않을 수 있다. 따라서 이 방법을 적용할 때는 데이터 특성을 충분히 검토하고, 필요 시 보완적인 검정을 병행하는 것이 바람직하다.
전반적으로, 이 논문은 서열형 질적 데이터를 비교하는 새로운 시각을 제공하며, 특히 임상 연구자가 이미 익숙한 생존분석 도구를 활용함으로써 결과 해석과 보고가 간편해진다는 실용적 가치를 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기