대규모 유전자 발현 데이터용 확장 가능한 서브스페이스 클러스터링 KiWi
KiWi는 OPSM(순서 보존 서브매트릭스) 기반의 서브스페이스 클러스터링 알고리즘으로, 수만 개 유전자와 수천 개 실험 조건을 포함하는 대규모 발현 데이터에서도 효율적으로 작동한다. 작은 규모의 ‘twig’ 클러스터(몇 개 유전자가 다수의 조건에서 동일한 순서를 보이는 경우)를 탐지하고, 양·음의 상관관계를 모두 포착한다. 실험에서는 중복 프로브의 동일 클러스터 배정, 임상 메타데이터와의 연관성, 실제 프로모터와 음성 대조군 구분, cis‑R…
저자: ** - **Obi L. Griffith** (BC Cancer Agency, Canada) - **Byron J. Gao** (Texas State University – San Marcos, USA) - **Mikhail Bilenky** (BC Cancer Agency
본 논문은 유전자 발현 데이터의 급격한 규모 확대에 대응하기 위해, 기존 OPSM(순서 보존 서브매트릭스) 기반 서브스페이스 클러스터링 방법의 한계를 극복한 새로운 알고리즘 KiWi를 제안한다. 서론에서는 전통적인 전역 클러스터링이 유전자의 다중 기능성과 조건별 발현 차이를 반영하지 못한다는 점을 지적하고, 서브스페이스 클러스터링, 특히 OPSM이 이러한 문제를 해결할 수 있는 유망한 모델임을 설명한다. 그러나 기존 OPSM 탐색 기법은 데이터 규모가 커질수록 연산량이 기하급수적으로 증가하고, 특히 ‘트위그 클러스터’(소수 유전자가 다수 실험 조건에서 동일한 순서를 보이는 경우)를 탐지하는 데 비용이 과다해 실질적으로 배제된다는 문제점이 있다.
이에 저자들은 두 단계의 효율적인 탐색 프레임워크를 설계하였다. 첫 단계에서는 사용자 정의 파라미터 k(패턴 길이 제한)와 w(최소 클러스터 크기)를 이용해 후보 패턴을 빠르게 필터링한다. 이때 각 유전자 행을 정렬한 뒤, 순서 일치 여부를 비트맵 형태로 압축 저장해 메모리 사용을 최소화한다. 두 번째 단계에서는 남은 후보에 대해 실제 순서 일치를 검증하고, 양의 상관뿐 아니라 역순(음의 상관)도 동일한 OPSM 모델에 포함시켜 탐색한다. 이러한 설계는 트위그 클러스터를 포함한 모든 형태의 서브스페이스 패턴을 선형 시간에 가깝게 탐색할 수 있게 하며, 일반 PC에서도 10 000 ~ 100 000개의 유전자와 1 000 ~ 10 000개의 실험 조건을 가진 데이터셋을 24~48시간 내에 처리하도록 한다.
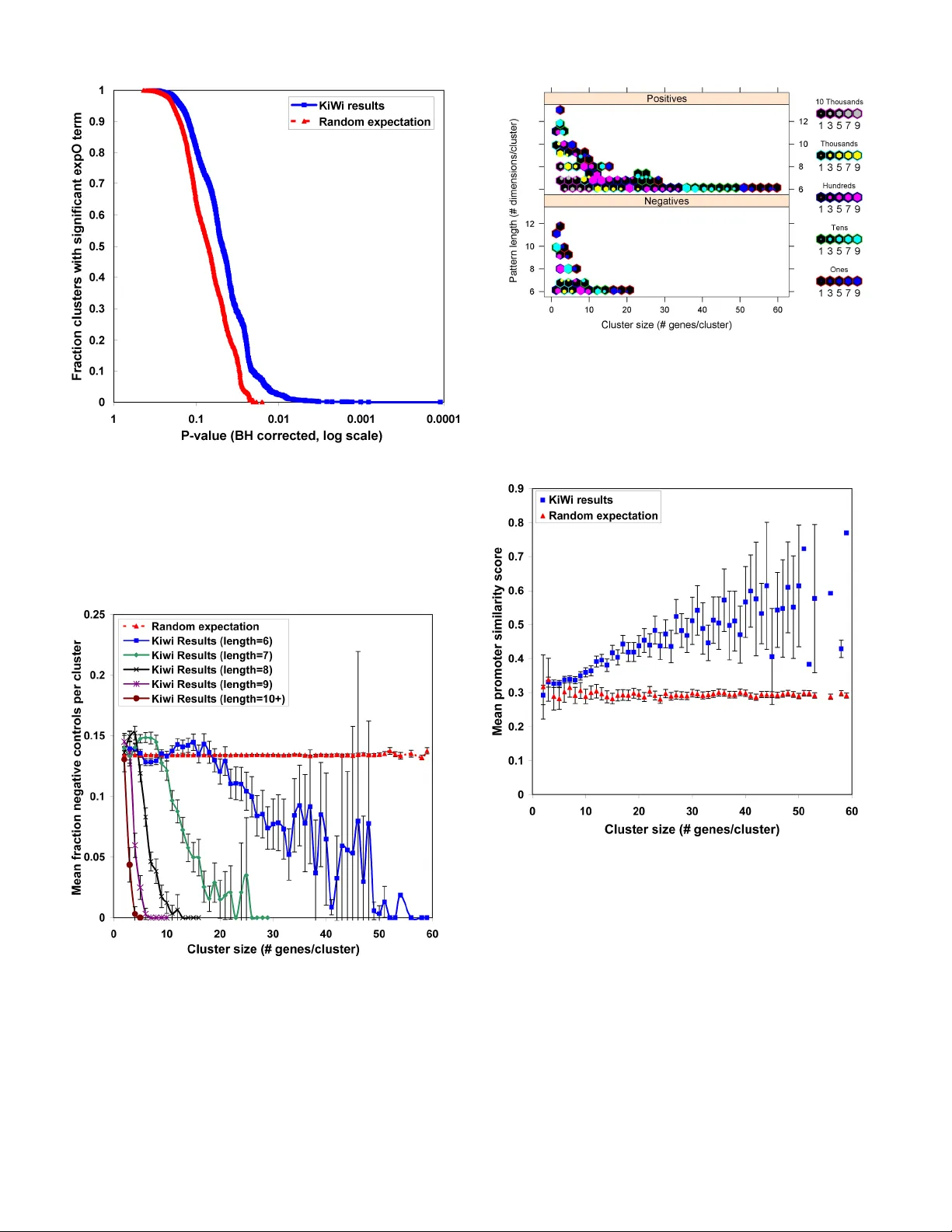
실험에서는 세 개의 실제 데이터셋을 사용하였다. 첫 번째는 Affymetrix GPL96 마이크로어레이 데이터(수천 개 유전자, 수백 개 실험), 두 번째는 expO 데이터(수만 개 유전자, 수천 개 실험), 세 번째는 Cooper 프로모터 데이터(수백 개 프로모터, 16개 세포주)이다. KiWi는 각각 13 412, 212 532, 45 678개의 클러스터를 도출했으며, 평균 유전자 수는 5.1, 3.9, 6.8, 평균 패턴 길이는 24.0, 42.5, 6.9였다. 특히, 트위그 클러스터가 전체 클러스터의 80% 이상을 차지했으며, 이들 클러스터는 5~10개의 유전자가 10~120개의 실험 조건에서 동일한 순서를 보이는 특징을 가졌다.
생물학적 타당성 검증으로는 네 가지 실험을 수행하였다. (1) 중복 프로브 검증: expO 데이터에서 전체 클러스터 중 7.9%가 동일 유전자의 중복 프로브를 포함했으며, 이는 무작위 시뮬레이션 대비 유의미하게 높은 비율이었다. (2) 실험 메타데이터 연관성: 조직 출처, 성별, 흡연 여부 등 임상 변수와 클러스터가 강하게 연관됨을 통계적으로 확인하였다(p = 0.009). (3) 음성 대조 프로모터 분석: Cooper 데이터에서 음성 대조 서열이 클러스터에 포함될 확률이 무작위 대비 현저히 낮았으며, 클러스터 크기와 패턴 길이가 증가할수록 음성 서열 포함 비율이 감소하였다. (4) cisRED 모티프 분석: KiWi 클러스터의 프로모터 서열이 무작위 대비 높은 보존 모티프 점수를 얻었으며, 클러스터 크기와 실험 차원이 늘어날수록 차이가 더욱 두드러졌다.
논의에서는 KiWi가 기존 OPSM 기반 방법보다 확장성, 트위그 클러스터 탐지, 양·음 상관 포착 측면에서 우수함을 강조한다. 파라미터 k와 w를 조절함으로써 사용자는 탐색 깊이와 클러스터 품질을 자유롭게 조정할 수 있다. 또한, KiWi는 중복 프로브를 사전에 제거하거나 평균화하지 않아도 효율적인 클러스터링이 가능함을 보여, 실제 연구에서 전처리 비용을 절감한다. 저자들은 KiWi가 대규모 데이터에서 전통적인 전역 클러스터링이 놓치기 쉬운 조건 특이적 코레귤레이션을 발견하는 데 특히 유용하다고 주장한다. 마지막으로, KiWi의 오픈소스 구현과 실행 파일을 제공함으로써 생물정보학 커뮤니티가 손쉽게 접근하고 확장할 수 있도록 지원한다.
결론적으로, KiWi는 대규모 유전자 발현 데이터에서 효율적으로 서브스페이스 클러스터를 탐색하고, 생물학적으로 의미 있는 트위그 클러스터와 양·음 상관 패턴을 동시에 포착함으로써, 차세대 바이오마커 탐색 및 시스템 생물학 연구에 강력한 도구가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기