분산 라벨링의 효율적 인간 계산
초록
본 논문은 다수의 비협조적 교사들이 제공한 라벨을 전역적으로 일관되게 정합하는 방법을 제시하고, 라벨 효율성을 α = l⁄c 로 정의하여 알고리즘별 효율 한계를 분석한다. C³ 알고리즘과 대표자 알고리즘을 제안하고, 최적 효율 상한 f⁎(α) ≤ min(2α⁄(1+α), 1) 를 증명한다. 또한 교사 간 부분적 라벨 일치 확률 p 를 고려한 확장 모델도 제시한다.
상세 분석
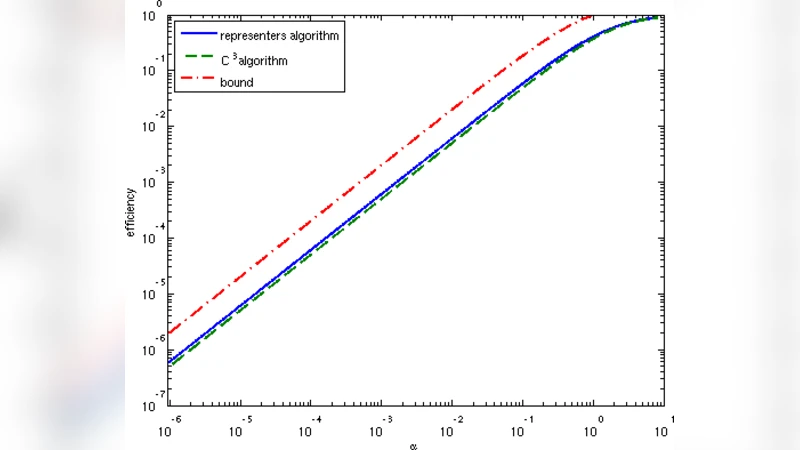
이 논문은 대규모 데이터셋을 구축할 때 발생하는 “분산 라벨링” 문제를 이론적으로 정형화한다. 라벨 효율성 f(α,alg)은 전체 라벨 중 전역적으로 일관된 라벨이 차지하는 비율로 정의되며, α = l⁄c (교사가 라벨링할 수 있는 샘플 수 l 과 전체 클래스 수 c 의 비율) 가 핵심 파라미터이다. α가 클수록 동일 교사 내에서 다양한 클래스를 관찰하게 되므로, 서로 다른 교사 간 라벨 충돌을 해결하기 쉬워진다.
제안된 첫 번째 알고리즘인 C³(Contradict the Connected Components) 은 무방향 그래프를 이용한다. 초기에는 모든 샘플을 정점으로 두고, 한 교사에게 l개의 샘플을 무작위로 할당한다. 교사가 동일 라벨을 부여한 두 정점은 하나의 정점으로 병합하고, 서로 다른 라벨을 부여한 경우는 간선으로 연결한다. 이 과정을 그래프가 완전 클리크가 될 때까지 반복한다. 클리크가 되면 각 정점에 고유 라벨을 부여하고, 병합된 정점들의 라벨을 전파한다. 분석에 따르면, 한 라운드당 평균 병합되는 정점 수는 l·Q(α) 로, Q(α)= (1‑exp(‑α))/α 이다. 따라서 전체 라벨 수는 n·
댓글 및 학술 토론
Loading comments...
의견 남기기