대규모 표본을 위한 CLT 기반 R 패키지 asympTest의 설계와 활용
본 논문은 중심극한정리(CLT)를 이용해 평균·분산·그 차이·비율 등에 대한 대규모 표본 검정과 신뢰구간을 제공하는 R 패키지 **asympTest**를 소개한다. 특히 분산 검정에서 비정규성에 대한 강건성을 쿠투시스(kurtosis)로 정량화하고, 기존 χ²·F 검정의 한계를 극복한다.
저자: Jean-Franc{c}ois Coeurjolly (LJK), Remy Drouilhet (LJK), Pierre Lafaye De Micheaux (LJK)
본 논문은 중심극한정리(CLT)를 기반으로 한 대규모 표본 검정과 신뢰구간 추정 방법을 구현한 R 패키지 **asympTest**를 소개한다. 연구 배경으로는 기존의 분산 검정(χ² 검정)과 두 표본 분산 비율 검정(Fisher 검정)이 정규성 가정에 매우 민감하여, 비정규 데이터가 존재할 경우 제1종 오류가 크게 증가한다는 점을 들었다. 저자들은 이러한 문제를 해결하기 위해 “CLT 절차”라는 통일된 프레임워크를 제시한다.
프레임워크는 다음과 같다. 관심 매개변수 θ(평균, 분산, 평균 차이, 분산 차이, 평균 비율, 분산 비율)를 추정량 θ̂와 그 표준오차 σ̂θ로 표현하고, (θ̂‑θ)/σ̂θ 를 표준정규분포 근사치로 사용한다. 이때 표준오차는 각각의 매개변수에 대한 이론적 분산식에 기반해 추정한다. 표본 평균과 평균 차이에 대해서는 기존 t‑검정과 동일한 형태를 유지하면서, 비정규성에 대한 강건성을 확보한다.
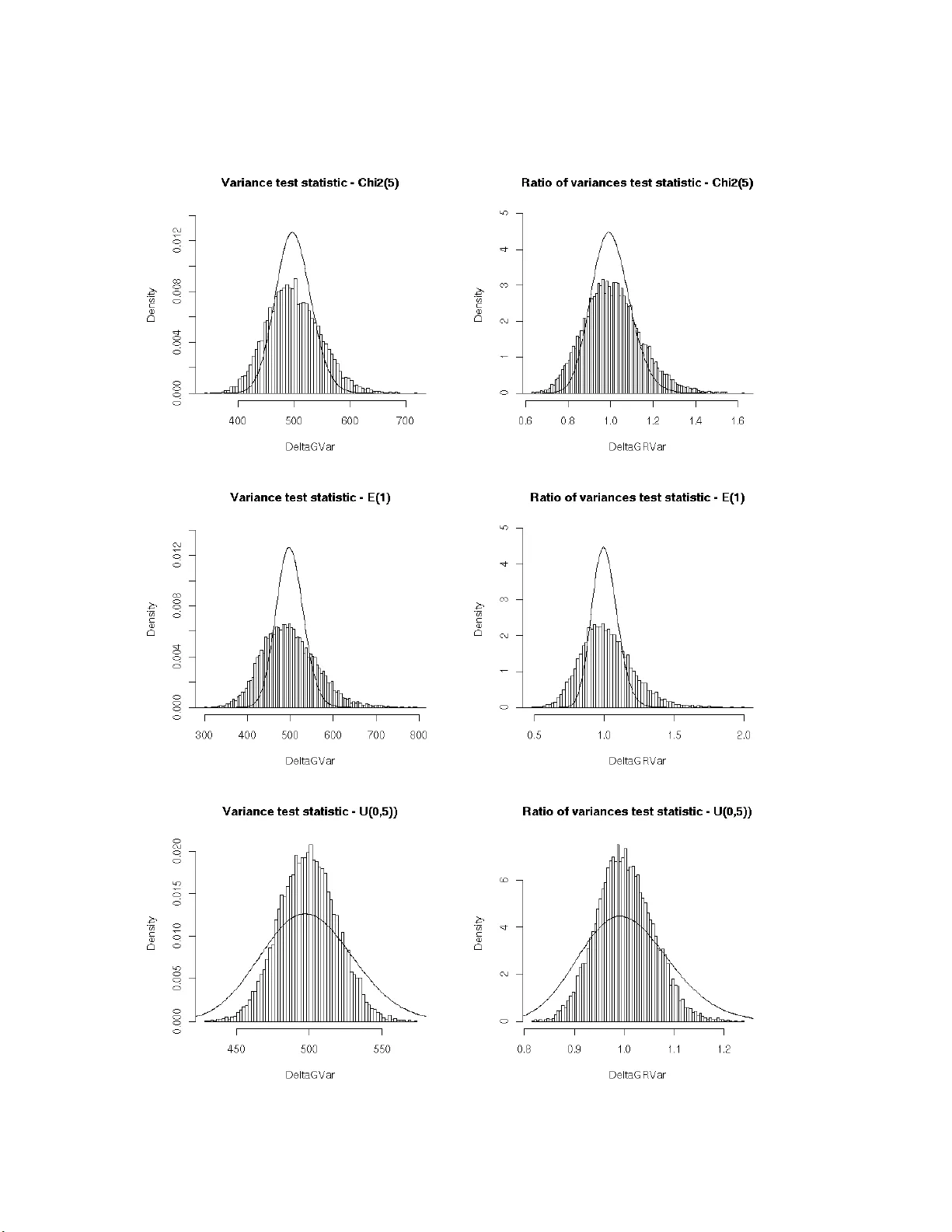
특히 분산 검정과 분산 비율 검정에 대해서는 기존 χ²·분산 검정과 Fisher·비율 검정이 비정규성에서 asymptotic variance가 쿠투시스(k)‑1 배만큼 커짐을 수식(1)·(2)로 증명한다. 정규분포(k=3)에서는 기존 검정과 동일하지만, 꼬리가 두꺼운 분포에서는 검정통계량이 과도하게 변동한다. 이를 보완하기 위해 asympTest는 표본 분산 s²에 대한 CLT 기반 검정통계량 Λ̂ = (n‑1)·s²/σ₀ 를 사용하고, 그 표준오차를 쿠투시스에 의존하는 식으로 계산한다. 결과적으로 비정규성에 강건한 분산 검정과 두 표본 분산 비율 검정을 제공한다.
패키지 구현은 `asymp.test` 함수를 중심으로 이루어진다. 주요 인자는 기존 R 함수(`t.test`, `var.test`)와 유사하게 `x`, `y`, `parameter`, `alternative`, `reference`, `conf.level`, `rho` 등을 포함한다. `parameter`는 “mean”, “var”, “dMean”, “dVar”, “rMean”, “rVar” 중 하나를 선택한다. `rho` 파라미터는 가중 평균·분산 차이 검정에서 두 표본의 상대적 가중치를 조정한다. 보조 함수들(`seMean`, `seVar`, `seDMean`, `seDVar`, `seRMean`, `seRVar`)은 각각의 매개변수에 대한 표준오차를 계산한다.
시뮬레이션 결과에서는 χ²·분산 검정과 Fisher·비율 검정이 비정규 데이터(χ²(5), 지수분포, 균등분포)에서 p‑값이 크게 왜곡되는 반면, asympTest 기반 검정은 표준정규 근사에 의해 p‑값과 신뢰구간이 안정적으로 유지됨을 보여준다. 또한, 실제 데이터 예시로 iris 데이터셋을 이용해 평균, 평균 차이, 평균 비율 등에 대한 검정을 수행하고, 결과가 직관적으로 해석될 수 있음을 시연한다.
교육적 관점에서는 평균 검정이 전통적인 t‑검정과 동일한 수식적 형태를 유지하면서, 비정규성에 대한 논의를 자연스럽게 포함시킬 수 있다. 이는 통계 교육에서 “정규성 가정이 필요 없는” 검정 방법을 소개하는 좋은 사례가 된다.
결론적으로, 이 논문은 대규모 데이터 분석에서 정규성 가정에 얽매이지 않는 검정 도구를 제공함으로써 통계 연구·실무·교육 모두에 실질적인 가치를 제공한다. 특히, 분산 검정의 비정규성 민감도를 쿠투시스로 정량화한 점은 향후 강건 통계 방법론 개발에 중요한 이정표가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기