제프리스 발산 기반 사전의 일반화와 베이지안 가설 검정 적용
본 논문은 모델 간 발산 측도를 이용해 객관적이고 정상적인 사전분포(DB prior)를 정의한다. 대칭 KL 발산을 정규화한 단위 발산 \(\bar D\)와 꼬리 두께를 조절하는 함수 \(h_q(t)=(1+t)^{-q}\)를 결합해 \(\pi_D(\theta)\propto h_{q^*}(\bar D(\theta,\theta_0))\pi_N(\theta)\) 형태의 사전을 제시한다. 정상선형 모델에서는 기존의 Jeffreys‑Zellner‑Sio…
저자: M.J. Bayarri, G. Garcia-Donato
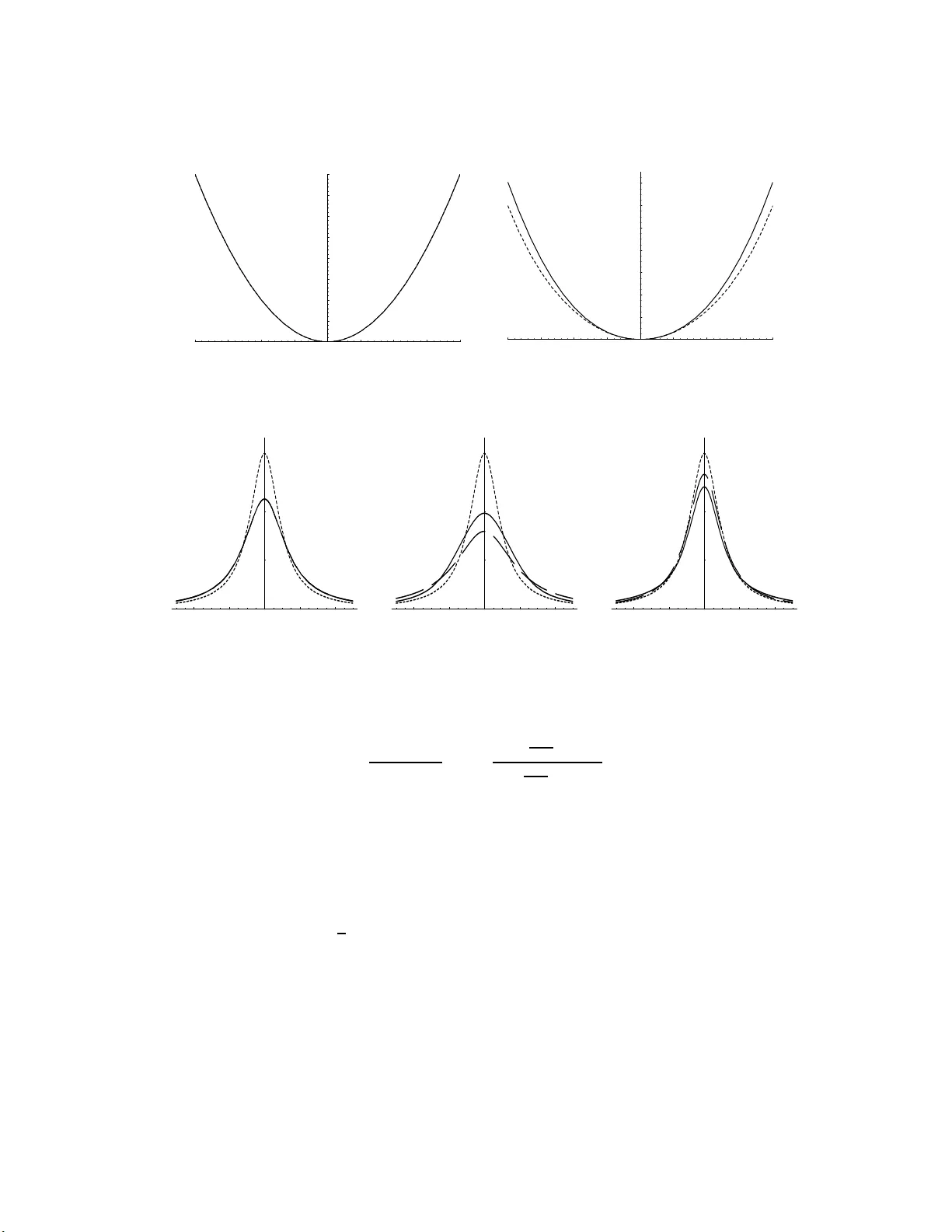
본 논문은 베이지안 가설 검정·모델 선택에서 객관적이고 정상적인 사전분포를 정의하기 위해, 두 경쟁 모델 사이의 발산을 직접 활용하는 새로운 프레임워크인 Divergence‑Based (DB) priors를 제안한다.
1. **문제 설정 및 기존 접근법의 한계**
- 가설 검정 \(H_1:\theta=\theta_0\) vs \(H_2:\theta\neq\theta_0\) 혹은 모델 선택 \(M_1\) vs \(M_2\) 형태를 고려한다.
- 기존의 비정보적(prior) 사전(예: Jeffreys, uniform)은 모델 불확실성 상황에서 부적절하거나 임의적인 상수에 민감해 잘못된 Bayes factor를 초래한다.
- 객관적 Bayes factor를 얻기 위한 방법으로 Intrinsic prior, Fractional prior, Expected posterior prior 등이 제안됐지만, 이들 역시 불규칙 모델이나 혼합 모델에서는 정의가 어려운 경우가 있다.
2. **발산 기반 사전의 정의**
- 두 모델의 확률밀도 \(f(y|\theta_0)\)와 \(f(y|\theta)\) 사이의 KL 발산을 이용한다.
- 비대칭성을 없애기 위해 합발산 \(D_S\)와 최소발산 \(D_M\)를 정의하고, 이를 표본 크기 \(n^*\) 로 정규화해 단위 발산 \(\bar D = D/n^*\)를 만든다.
- \(\bar D\)는 모델 간 차이를 표준화된 스케일로 측정하므로, 사전은 \(\pi_D(\theta)\propto h(\bar D(\theta,\theta_0))\pi_N(\theta)\) 형태가 된다. 여기서 \(\pi_N\)는 일반적인 객관적 추정 사전(Jeffreys, Haar 등)이며, \(h\)는 감소 함수이다.
3. **함수 \(h\)와 꼬리 두께 조절**
- \(h_q(t)=(1+t)^{-q}\)를 선택한다. \(q\)는 정규화 상수 \(c(q)=\int h_q(\bar D)\pi_N(\theta)d\theta\) 가 유한하도록 최소값을 찾는다.
- 최종 사전은 \(q^*=q+1/2\)를 사용해 \(\pi_D(\theta)=c(q^*)^{-1}h_{q^*}(\bar D(\theta,\theta_0))\pi_N(\theta)\) 로 정의한다.
- \(1/2\)를 더하는 이유는 정규선형 모델에서 Jeffreys‑Zellner‑Siow (JZS) 사전과 정확히 일치시키기 위함이며, 일반적으로 \(0<\delta<1\) (즉, \(q^*=q+\delta\))를 선택하면 heavy‑tail 사전이 얻어진다.
4. **위치·스케일 파라미터에 대한 구체적 적용**
- 위치 파라미터(예: 정규 평균)에서는 \(\pi_N(\theta)=1\) 로 두고, \(\pi_D(\theta)\)는 \(\theta_0\)를 중심으로 대칭·단봉 형태가 된다.
- 스케일 파라미터는 로그 변환을 통해 위치 파라미터로 바꾸고, 변환 불변성에 따라 \(\pi_D(\theta)\propto h_{q^*}(\bar D(\theta,\theta_0))/\theta\) 로 얻는다.
- 일반 파라미터에 대해서는 \(\xi=g(\theta)\) 라는 변환을 찾아 \(\xi\)를 위치 파라미터로 간주하고 동일한 절차를 적용한다.
5. **일반 파라미터와 누락 파라미터(노이즈 파라미터) 처리**
- 누락 파라미터가 존재할 경우, \(\pi_N(\theta,\nu)\) 를 먼저 정의하고, \(\bar D\) 를 \((\theta,\nu)\) 전체에 대해 계산한다.
- 변환 불변성을 유지하면 최종 DB 사전은 \(\pi_D(\theta,\nu)\propto h_{q^*}(\bar D(\theta,\nu;\theta_0,\nu_0))\pi_N(\theta,\nu)\) 가 된다.
6. **성질 및 이론적 결과**
- **존재성**: \(q<\infty\)이면 정규화 상수 \(c(q^*)\) 가 유한하고 사전이 정상화 가능하다.
- **대칭·단봉**: 정의에 따라 \(\pi_D(\theta)\)는 \(\theta_0\)를 중심으로 대칭이며, 단봉성을 만족한다.
- **정보 일관성**: 제한된 표본에서도 Bayes factor가 올바른 모델을 선호하도록 증명하였다.
- **불규칙·혼합 모델**: \(D_M\) 은 지원이 겹치지 않을 때도 정의 가능하므로, 혼합 모델 등에서 기존 사전이 실패하는 경우에도 DB 사전이 정상적으로 작동한다.
7. **계산적 접근**
- 정규화 상수 \(c(q^*)\) 를 MCMC 샘플링을 통해 추정하는 방법을 제시하고, 라플라스 근사를 이용한 대수적 표현을 제공한다.
- 선형 회귀 모델에서는 \(\bar D\) 가 정확히 \(\frac{g}{1+g}\) 형태가 되며, 결과적으로 DB 사전이 기존 JZS 사전과 동일함을 증명한다.
- 실제 데이터와 시뮬레이션을 통해 DB 사전 기반 Bayes factor가 Intrinsic prior, Fractional prior 등과 유사한 성능을 보이면서도 불규칙 상황에서 더 안정적임을 확인하였다.
8. **결론 및 의의**
- Jeffreys가 제시한 “발산을 이용한 사전” 아이디어를 현대 베이지안 모델 선택에 체계적으로 확장하였다.
- DB 사전은 기존의 여러 객관적 사전과 거의 동일한 성질을 가지면서, 특히 불규칙·혼합 모델에서 정의가 가능하고, 꼬리 두께를 조절해 초소표본 일관성을 보장한다.
- 따라서 베이지안 가설 검정·모델 선택에서 사전 선택에 대한 불확실성을 크게 감소시키는 실용적인 도구가 된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기