지식 공간 내 데이터 임베딩
초록
본 논문은 전자과학(e‑Science) 환경에서 데이터와 메타데이터를 통합적으로 관리하기 위해 RDF 기반의 전역 식별자와 콘텐츠 저장소를 결합한 오픈소스 프레임워크인 Tupelo를 소개한다. Tupelo는 데이터, 문서, 워크플로, 인물, 프로젝트 등 다양한 엔티티와 프로벤언스, 사회·지리·시간 관계 등 풍부한 메타데이터를 하나의 지식 공간에 안전하게 저장·연결한다.
상세 분석
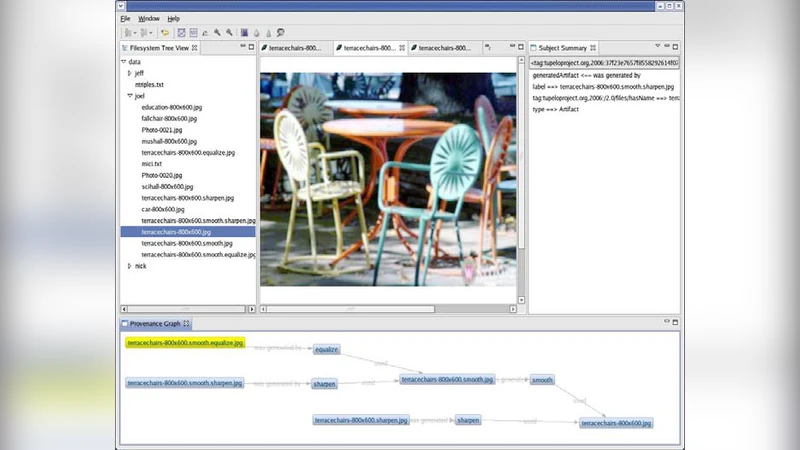
Tupelo 프레임워크는 기존의 파일‑기반 혹은 데이터베이스‑중심 콘텐츠 관리 시스템(CMS)이 갖는 한계를 극복하기 위해 설계되었다. 핵심 설계 원칙은 “전역 식별자(Global Identifier, URI)와 RDF 트리플을 이용한 의미론적 연결”이며, 이를 통해 서로 다른 물리적 위치에 존재하는 리소스들을 논리적으로 하나의 그래프 형태로 통합한다. 첫 번째 특징은 집계 가능한(content aggregatable) 저장소 모델이다. 이는 단일 리포지터리뿐 아니라 분산된 저장소(예: 로컬 파일시스템, 클라우드 객체 스토리지, 데이터베이스)들을 추상화 레이어 아래에 묶어, 클라이언트는 동일한 API로 모든 리소스에 접근할 수 있게 한다. 두 번째 특징은 보안 및 접근 제어 메커니즘이다. Tupelo는 RDF 메타데이터에 기반한 정책 엔진을 제공해, 사용자·그룹·역할 기반의 세밀한 권한 부여를 가능하게 한다. 세 번째는 다양한 메타데이터 스키마 지원이다. 프로벤언스(Prov-O), FOAF, GeoSPARQL, OWL 등 표준 온톨로지를 그대로 활용하면서도 도메인 특화 어휘를 손쉽게 확장할 수 있다. 특히, 시간·공간 관계를 표현하기 위한 시계열 트리플과 지리적 좌표 트리플을 동시에 관리함으로써, 복합적인 과학 워크플로우(예: 센서 데이터 수집 → 시뮬레이션 → 결과 시각화)에서 발생하는 복잡한 의존성을 명시적으로 모델링한다.
기술 구현 측면에서 Tupelo는 Jena 기반 RDF 스토어와 Apache Jackrabbit 같은 JCR(Java Content Repository) 를 결합한다. RDF 트리플은 Jena TDB 혹은 Blazegraph에 저장되고, 실제 파일·바이너리 데이터는 JCR에 보관된다. 이중 저장 구조는 메타데이터 검색 성능을 최적화하면서도 대용량 바이너리 파일을 효율적으로 관리한다. 또한, RESTful API와 SPARQL 엔드포인트를 제공해, 외부 애플리케이션(예: Jupyter Notebook, 워크플로 엔진)과의 연동을 단순화한다.
실제 적용 사례로는 천문학 데이터 파이프라인, 지리정보 시스템(GIS) 기반 환경 모니터링, 그리고 생명과학 프로젝트에서의 협업 플랫폼 구축이 언급된다. 각 사례에서 Tupelo는 데이터의 장기 보존(디지털 보존 정책 적용), 메타데이터 기반 자동 재현성(워크플로 재실행), 그리고 다학제 팀 간의 의미론적 협업(공동 어휘 정의) 등을 실현하였다.
결론적으로, Tupelo는 “데이터는 발견 가능하고, 접근 가능하며, 이해 가능해야 한다”는 e‑Science의 핵심 요구를 만족시키는 통합 인프라스트럭처를 제공한다. 전통적인 파일 시스템이나 단일 메타데이터 레지스트리와 달리, 의미론적 그래프와 집계 가능한 저장소를 결합함으로써, 분산된 과학 공동체가 장기적으로 데이터를 재사용하고, 새로운 지식을 창출할 수 있는 기반을 마련한다.
댓글 및 학술 토론
Loading comments...
의견 남기기