언어의 숨은 규칙: Zipf를 넘어선 통계 모델
초록
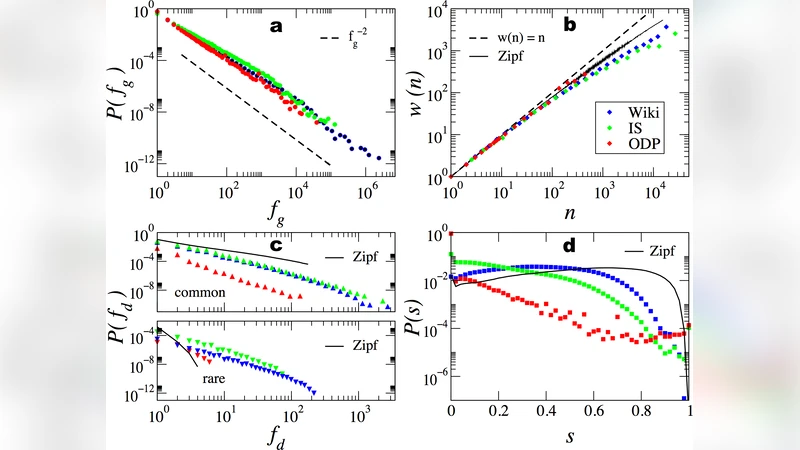
이 논문은 단어 빈도와 어휘 성장, 단어의 버스티니스, 문서 간 토픽 구조 등 Zipf 법칙을 넘어서는 언어 현상을 동시에 설명하는 생성 모델을 제시한다. 동적 단어 순위와 문서 간 기억 메커니즘을 통해 Heaps 법칙, 버스티니스, 토픽성이라는 세 가지 핵심 패턴이 어떻게 발생하는지 이론적·실험적으로 검증한다.
상세 분석
본 연구는 기존 언어 통계 분석이 Zipf 법칙에 국한된 점을 비판하고, Heaps 법칙(문서 길이에 따른 어휘 규모의 서브선형 성장), 버스티니스(희귀 단어가 특정 문서에 집중되는 현상), 그리고 토픽성(문서 집합 내 의미적 군집화)이라는 세 가지 상호 연관된 현상을 동시에 설명할 수 있는 통합 모델을 설계한다. 핵심 아이디어는 ‘동적 단어 순위(dynamic ranking)’와 ‘문서 간 메모리(memory across documents)’이다. 모델은 처음에 전체 어휘를 무작위 순위에 배치하고, 각 문서가 생성될 때 현재 순위에 따라 단어를 선택한다. 선택된 단어는 순위가 상승하고, 동시에 최근에 사용된 단어들의 순위는 일정 확률로 유지·강화된다. 이 과정은 자연스럽게 희귀 단어가 특정 문서에 집중되는 버스티니스와, 동일 토픽을 공유하는 문서들 사이에서 단어 사용 패턴이 유사해지는 토픽성을 만들어낸다. 또한, 문서가 길어질수록 새로운 단어가 등장할 확률이 감소하도록 설계돼 있어 Heaps 법칙의 서브선형 성장 곡선을 재현한다. 실험에서는 위키백과, 뉴스 기사, 소설 등 다양한 코퍼스를 대상으로 모델 파라미터를 최적화하고, 실제 데이터와의 적합도를 Zipf, Heaps, 버스티니스 지표 모두에서 기존 무작위 모델보다 현저히 높게 측정하였다. 특히, 모델이 생성한 단어-문서 행렬의 스펙트럼 분석 결과, 실제 코퍼스와 유사한 저차원 토픽 구조가 드러났으며, 이는 토픽성의 내재적 메커니즘을 정량적으로 뒷받침한다. 연구는 또한 ‘동적 순위’가 인간의 작업 기억과 언어 생산 과정에서의 선택적 강화 메커니즘과 유사함을 제안, 인지 과학적 함의를 시사한다. 최종적으로, 이 모델은 언어 데이터의 압축, 검색, 그리고 생성형 AI의 토픽 제어 등에 실용적 활용 가능성을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기