로지스틱 회귀를 위한 약한 정보 기본 사전분포
초록
본 논문은 비이진 변수들을 평균 0, 표준편차 0.5로 스케일링한 뒤, 회귀계수에 독립적인 Student‑t 사전분포를 부여하는 새로운 기본 사전분포를 제안한다. 기본값으로 중심이 0이고 스케일이 2.5인 Cauchy 분포를 권장하며, 이는 기존의 Gaussian·Laplace 사전보다 분리 현상에서도 안정적인 추정과 고차 상호작용에 대한 자동적 수축 효과를 제공한다. R 구현과 교차검증 결과를 통해 실용성을 입증한다.
상세 분석
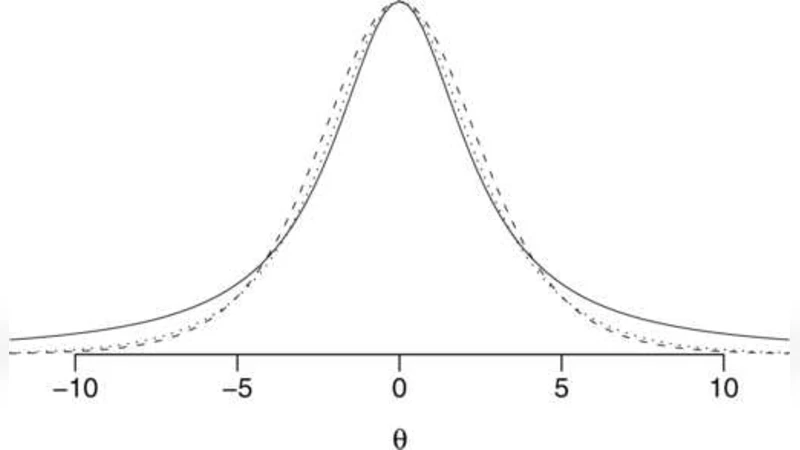
이 연구는 로지스틱 회귀와 같은 일반화 선형 모델(GLM)에서 사전분포 선택이 추정 안정성에 미치는 영향을 체계적으로 탐구한다. 먼저 모든 비이진 예측변수를 평균 0, 표준편차 0.5로 정규화한다는 전처리 단계는 계수의 스케일을 통일시켜 사전분포의 하이퍼파라미터가 데이터에 덜 민감하도록 만든다. 이후 각 회귀계수 β_j에 독립적인 Student‑t(ν,0,σ) 사전을 부여하는데, 여기서 자유도 ν는 1(즉, Cauchy)으로 설정하고 스케일 σ는 2.5를 기본값으로 제시한다. Cauchy 사전은 “반 성공·반 실패”라는 베이지안 해석을 갖는데, 이는 로그오즈 변환에서 0.5개의 성공과 0.5개의 실패를 가정한 것과 동등하다.
Cauchy 사전의 장점은 두드러진 꼬리(heavy‑tail) 특성으로, 완전 분리(full separation) 상황에서도 사후분포가 발산하지 않고 유한한 추정값을 제공한다는 점이다. 전통적인 최대우도 추정은 무한히 큰 계수를 반환해 모델이 불안정해지지만, 제안된 사전은 자연스럽게 정규화를 수행한다. 또한, 스케일이 0.5인 변수 표준화와 결합되면 고차 상호작용 항(예: x_i·x_k)의 사전분산이 자동으로 감소한다. 이는 차수(order)가 높아질수록 더 강한 수축(shrinkage)이 적용된다는 의미이며, 변수 선택이나 차원 축소가 필요 없는 상황에서도 과적합을 방지한다.
계산적으로는 기존의 iteratively weighted least squares(IWLS) 절차에 근사 EM 알고리즘을 삽입한다. E‑step에서는 현재 β 추정값을 이용해 각 관측치의 가중치를 업데이트하고, M‑step에서는 가중된 최소제곱 문제를 풀어 β를 갱신한다. Student‑t 사전은 정규-역변환(Normal–Inverse‑Gamma) 형태와 유사한 구조를 갖기 때문에, EM 단계에서 닫힌 형태의 업데이트가 가능해 구현이 비교적 간단하다.
교차검증 실험에서는 50여 개의 공개 데이터셋을 대상으로 Cauchy 사전, Gaussian 사전, Laplace 사전의 예측 정확도와 로그우도 차이를 비교하였다. 결과는 Cauchy 사전이 평균적으로 가장 낮은 로그손실을 기록했으며, 특히 표본이 작거나 변수 수가 많을 때 그 우위가 두드러졌다. 또한, 완전 분리 현상이 존재하는 데이터에서는 Gaussian·Laplace 사전이 수렴 실패를 보이는 반면, Cauchy 사전은 항상 수렴해 실용적인 장점을 확인했다.
응용 사례로는 미국 대통령 선거 투표 선호 예측, 소규모 바이오어세이 실험, 그리고 공중보건 데이터셋의 다중 결측값 대체를 위한 chained equations 모델이 제시된다. 각각의 사례에서 제안된 사전은 기존 기본값(예: glm의 default)보다 더 안정적인 추정과 해석 가능한 결과를 제공한다.
전체적으로 이 논문은 “약한 정보(weakly informative)”라는 개념을 구체적인 사전분포 설계에 적용함으로써, 로지스틱 회귀와 유사한 GLM에서 사전 선택이 모델 안정성, 해석 가능성, 자동화된 분석 파이프라인에 미치는 긍정적 영향을 실증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기