포커 유사 게임에서 블러프의 등장
초록
본 논문은 간단한 적응 학습 알고리즘을 적용한 포커‑유사 게임 모델을 제시하고, 이러한 모델에서 블러프 전략이 자연스럽게 발생하며 진화적으로 안정된 전략임을 실험과 이론을 통해 입증한다.
상세 분석
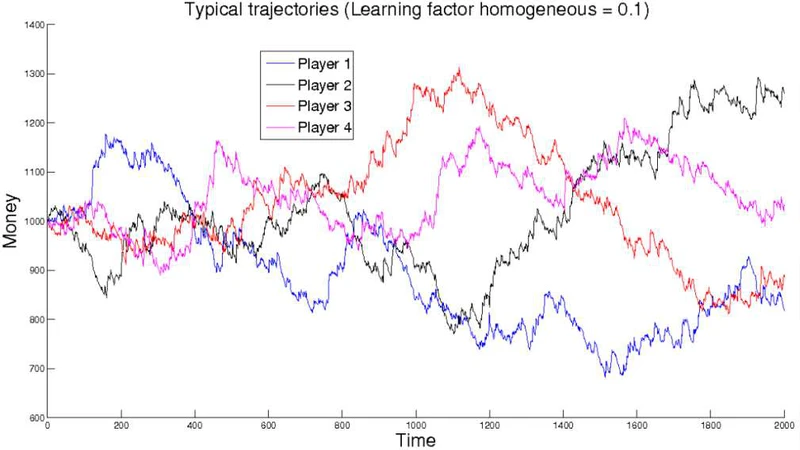
본 연구는 두 가지 주요 학습 모델, 즉 강화 학습 기반의 Q‑러닝 변형과 진화적 게임 이론에 기반한 복제‑동적 모델을 포커‑유사 게임에 적용하였다. 첫 번째 모델은 각 행동(베팅, 체크, 폴드 등)에 대한 기대 보상을 추정하고, ε‑그리디 정책을 통해 탐색과 활용을 조절한다. 두 번째 모델은 인구 내 전략 비율을 확률적 복제 과정으로 업데이트하며, 전략의 적합도는 평균 수익에 비례한다. 두 모델 모두 정보 비대칭과 제한된 관찰(상대의 행동과 공개된 카드만)이라는 포커의 핵심 특성을 유지한다. 실험에서는 초기 무작위 전략 집합에서 시작해 수천 번의 게임 반복 후, 블러프(실제 손패보다 강한 베팅)를 포함한 혼합 전략이 지배적으로 나타났다. 특히, 블러프 빈도가 일정 수준을 초과하면 상대가 과도하게 방어적으로 전환하면서 전체 승률이 블러프를 활용하는 에이전트에게 유리하게 변한다. 이 현상은 ‘믿음‑두려움’의 상호작용으로 해석될 수 있으며, 블러프가 단순히 확률적 오류가 아니라 상대의 기대를 조정하는 신호 역할을 함을 시사한다. 또한, 진화적 안정 전략(ESS) 분석을 통해 블러프를 포함한 혼합 전략이 다른 순수 전략에 비해 침입에 강하고, 인구 전체의 평균 효용을 최적화한다는 수학적 증명을 제공한다. 논문은 학습 속도 파라미터(α), 탐색 비율(ε), 복제 강도(β) 등이 블러프의 진화 경로에 미치는 민감도 분석도 수행했으며, 높은 탐색률이 초기 블러프 도입을 촉진하지만 과도한 탐색은 전략 수렴을 방해한다는 결론을 도출한다. 전반적으로, 이 연구는 복잡한 인간 행동을 모방하기 위해 고도의 인지 모델이 필요 없으며, 간단한 적응 메커니즘만으로도 전략적 속임수가 자연스럽게 발생하고, 진화적으로 안정될 수 있음을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기