사용자 지정 관계를 통한 플리커 기반 포크소니미 구축
초록
**
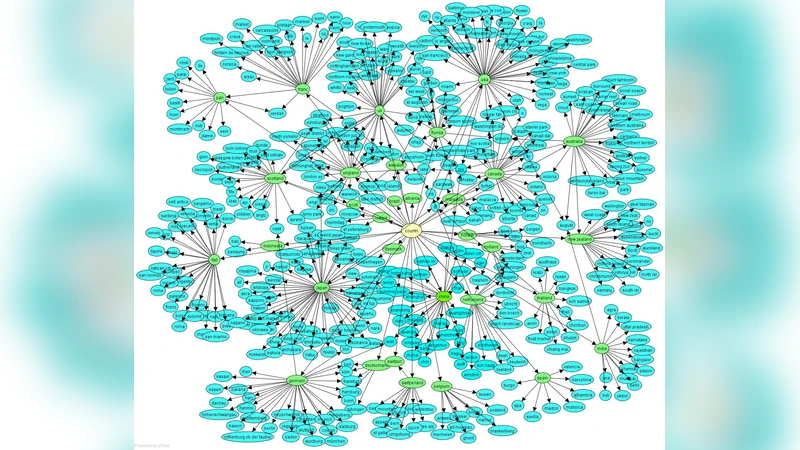
플리커 이용자들이 사진을 ‘컬렉션‑셋’ 구조로 조직하는 방식을 수집·정규화하고, 다수 이용자의 동의를 기반으로 상위‑하위 관계를 통계적으로 판단한다. 잡음과 충돌을 간단한 하드·소프트 제약으로 해결한 뒤, 불필요한 개념을 제거하고 연결해 비공식적인 분류 체계인 포크소니미를 자동 생성한다.
**
상세 분석
**
본 논문은 플리커(Flickr)에서 제공하는 “컬렉션‑셋” 계층 구조를 활용해 사용자들이 암묵적으로 표현한 상위‑하위(broader‑narrower) 관계를 대규모로 집계, 통합하는 방법을 제안한다. 핵심 아이디어는 (1) 용어 추출·정규화 단계에서 컬렉션·셋 이름을 토큰화하고, ‘&, :, /’ 등 구분자를 이용해 의미 단위를 분리한 뒤 Porter 스테머로 형태를 통일한다. 이 과정에서 대소문자, 구두점, 흔히 쓰이는 불용어를 제거해 동일 개념을 다양한 표기에서도 일관되게 매핑한다.
(2) 관계 충돌 해결 단계에서는 두 개념 A와 B 사이에 상하 관계가 상반될 경우, 이를 “노이즈”라고 가정하고 사용자 수 기반의 투표 메커니즘을 적용한다. 하드 제약(d₍A→B₎>1 ∧ d₍B→A₎≤1)과 소프트 제약(d₍A→B₎>1 ∧ d₍B→A₎≤d₍A→B₎)을 도입해 다수 의견이 강하게 지지하는 방향만을 유지한다. 이때 ‘1’이라는 최소 동의 수는 관계가 우연히 발생한 것이 아니라 실제 사용자의 의도임을 보장한다.
(3) 개념 정제·연결 단계에서는 관계 해소 후에도 “all set”, “occasion” 등 의미가 포괄적이면서 하위 개념이 거의 없는 노드들을 제거한다. 저자는 부모·자식 개수 비율을 휴리스틱으로 사용해 정보량이 낮은 노드를 식별하고, 남은 개념들을 트리 형태로 연결해 최종 포크소니미를 구성한다.
논문은 기존 연구와 차별화되는 점을 강조한다. 기존 태그 기반 방법은 인기‑일반성(popularity‑generality) 문제에 취약해 흔히 사용되는 일반 태그가 실제보다 상위 개념으로 오인된다. 반면 컬렉션‑셋 이름은 사용자가 직접 계층을 설계하기 때문에, 같은 용어가 상위·하위에 동시에 등장할 확률이 낮아 보다 신뢰성 있는 관계 추출이 가능하다. 또한, 기존의 온톨로지 정렬이나 깊은 계층 병합 기법과 달리, 이 연구는 수천 개의 얕은 계층을 동시에 다루며, 충돌 해결을 통계적 투표에만 의존함으로써 구현 복잡도를 크게 낮춘다.
한계점으로는 (i) 경로 선택 문제를 다루지 않아 동일 개념 간 다중 경로가 남을 수 있고, (ii) 의미적 동형어·다의어 처리(예: “Washington” vs “Washington State”)를 전혀 고려하지 않아 잠재적 오류가 존재한다는 점을 인정한다. 또한 정량적 평가가 부재해 실제 검색·추천 시스템에 적용했을 때의 효용성을 검증하지 못했다. 그럼에도 불구하고, 실험적 관찰을 통해 생성된 계층이 “합리적이고 비트리비얼하지 않다”는 직관적 결과를 제시함으로써 접근법의 가능성을 충분히 보여준다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기