ATLAS VO 성능 이질성 분석과 lmbench 기반 매칭 전략
초록
ATLAS 가상 조직(VO) 내 워크노드들의 CPU, 메모리, 네트워크 성능이 주문형 차이까지 존재함을 lmbench 마이크로벤치마크로 측정하였다. 정수·부동소수점 연산, 메모리 대역폭, 통신 지연 등에서 10배 이상 차이가 나타났으며, 이러한 이질성은 기존의 “모든 워크노드 동일” 혹은 SPEC 점수 기반 매칭이 비효율적임을 보여준다. 저자는 동적 성능 측정과 서브클러스터 기반 스케줄링을 제안한다.
상세 분석
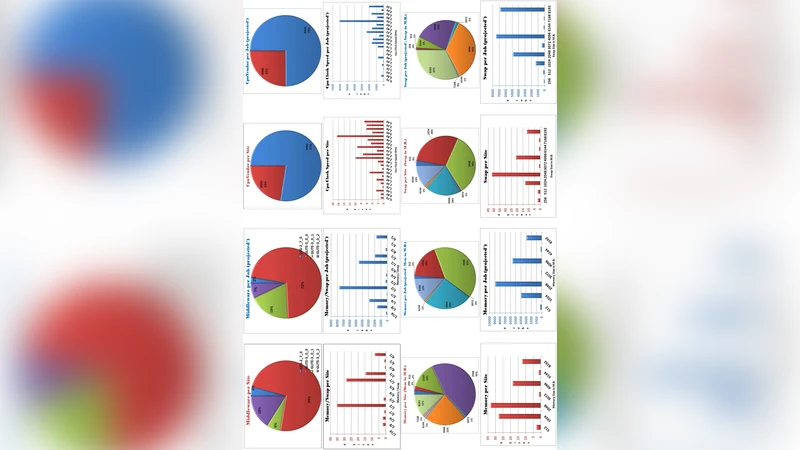
이 논문은 2007년 5월에 수행된 ATLAS VO(가장 큰 그리드 VO)의 실측 데이터를 기반으로, 워크노드(WN) 간 성능 이질성이 얼마나 심각한지를 정량적으로 밝힌다. 저자들은 lmbench‑3.0‑a4를 이용해 정수 64비트 곱셈(int64 mul), 부동소수점 곱셈(Float Mul, Double Mul), 64비트 정수 덧셈, 32·64비트 비트 연산, 그리고 STREAM 메모리 대역폭 테스트 등을 수행하였다. 결과는 크게 두 가지 특징을 보인다. 첫째, 같은 연산이라도 측정값이 두 개의 뚜렷한 클러스터(‘fast’와 ‘slow’)에 몰려 있어, 1.5 ns8.5 ns와 10 ns15 ns 사이에 명확한 구분이 존재한다. 이는 CPU 아키텍처 차이, 특히 EM64T/x86‑64 지원 여부에 기인한다는 추정이 제시된다. 둘째, 연산별 분포가 포아송이나 정규와 같은 알려진 통계적 패턴을 따르지 않으며, 0.3 ns~8.1 ns에 이르는 64비트 정수 덧셈처럼 1:25 이상의 비율 차이를 보인다. 이러한 비정형 분포는 작업 흐름이 특정 연산에 의존할 경우, 전체 작업 시간(T)이 노드 선택에 따라 2배, 심지어 10배까지 변동할 수 있음을 의미한다.
논문은 또한 그리드 인프라의 메타데이터가 부정확하거나 최신이 아니며, 운영 체제 배포판, 커널 버전, CPU 모델 등 기본 정보만을 제공한다는 점을 비판한다. 실제로 60 % 이상의 컴퓨팅 파워가 상위 10 % 사이트에 집중돼 있어, 자원 할당 효율이 크게 저하된다. 저자들은 이러한 상황을 개선하기 위해 두 가지 전략을 제시한다. (1) 서브클러스터 개념을 도입해 동일한 성능 특성을 가진 워커 노드들을 하나의 큐에 묶고, 큐‑레벨에서 성능 프로파일링을 수행한다. (2) lmbench와 같은 마이크로벤치마크를 지속적으로 실행해 실시간 성능 데이터베이스를 구축하고, 이를 JDL 파일이나 전역 스케줄러(RB, WMS)에 연계해 자동 매칭을 구현한다. 이렇게 하면, 예를 들어 부동소수점 연산이 지배적인 워크플로우에서는 Float‑Mul ≤ 3.5 ns인 노드만 선택해 전체 makespan을 크게 단축시킬 수 있다.
또한, 저자는 성능 이질성이 높은 클러스터에서는 작업 실패율이 상승하고, 특히 긴 실행 시간을 요구하는 과학 워크플로우(예: 지진, 해일 조기 경보)에서 급격한 지연이 발생할 위험을 강조한다. 따라서 “모든 워크노드가 동일하다”는 가정은 더 이상 타당하지 않으며, 동적 성능 측정 기반의 매칭 및 리소스 랭킹이 필수적이다. 마지막으로, 지속적인 벤치마크 수행이 시스템 부하의 0.5 % 이하로 유지될 수 있다는 점을 들어, 비용 대비 효과가 충분히 크다고 주장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기