모티프 모델 선택과 민감도 분석
본 논문은 유전자 서열에서 짧은 반복 패턴(모티프)을 찾는 문제에 대해 베이지안 접근법을 제안한다. 최대 사후 확률(MAP) 점수를 모델 선택 기준으로 사용하고, 이 기준이 모델 크기(모티프 수)를 올바르게 추정하는 조건을 이론적으로 분석한다. 또한 사전 하이퍼파라미터에 대한 민감도 분석을 수행해 실무에서 안정적인 사전 설정 방법을 제시한다.
저자: Mayetri Gupta
본 논문은 유전체 서열에서 짧은 반복 패턴, 즉 모티프를 탐지하는 문제를 베이지안 프레임워크 안에서 재정의하고, 모델 선택을 위한 새로운 기준을 제시한다. 서열 데이터를 하나의 긴 문자열 S로 보고, 이를 사전 D에 포함된 단어들의 연결로 모델링한다. 사전 D는 배경 문자(b=4 for DNA)와 여러 모티프 단어로 구성되며, 각 단어는 사용 빈도 ρ와, 모티프인 경우 위치별 문자 확률 행렬 Θ_k 로 파라미터화된다. ρ와 Θ_k 에는 각각 Dirichlet 사전분포를 부여해 사후분포가 다변량 베르누이(멀티노미얼) 형태로 유지되도록 설계하였다.
모델 선택은 두 가설 M0(배경만)와 M1(배경+단일 모티프) 사이의 베이즈 팩터 비율로 정의된다. 정확한 베이즈 팩터는 모든 가능한 단어 정렬을 적분해야 하므로 계산량이 급증한다. 이를 해결하기 위해 저자는 MAP 점수, 즉 사후 확률을 최대화한 정렬 A*에 대한 비율을 하한으로 사용한다. MAP 점수는 로그 형태로 전개될 때 Gamma 함수와 카운트 행렬을 포함한 명시적 식으로 표현되며, 이는 실제 계산이 가능하도록 만든다.
이론적 분석에서는 데이터 크기 N, 모티프 비율 c, 모티프 길이 w, 배경 문자 비율 θ0_i, 모티프 내 문자 비율 k_i 등을 이용해 MAP 발산 인자 r을 정의한다. Theorem 2.1에 따르면 r>0이면 MAP 점수가 N에 대해 지수적으로 무한히 커져, 충분히 큰 데이터에서는 MAP가 올바른 모델(모티프 존재 여부)을 일관적으로 선택한다. Theorem 2.2는 r의 최대값을 구하고, 배경이 균등하고 모티프가 각 문자당 동일하게 나타나는 경우 r이 양수가 되는 구체적인 식을 제시한다. 특히 “repeat‑based” 모티프(단일 문자 반복)는 균등 모티프에 비해 r이 작아 선택력이 약함을 보여준다.
다중 모티프 상황에 대해서는 Theorem 2.3이 제시된다. 새로운 모티프를 사전에 추가할 때, 실제 데이터에 해당 모티프가 존재한다면 MAP 점수가 지수적으로 증가한다는 것을 증명한다. 반대로 존재하지 않을 경우 MAP 점수는 감소한다. 이는 사전 확장 알고리즘이 진짜 모티프를 자동으로 포함하도록 하는 이론적 근거가 된다.
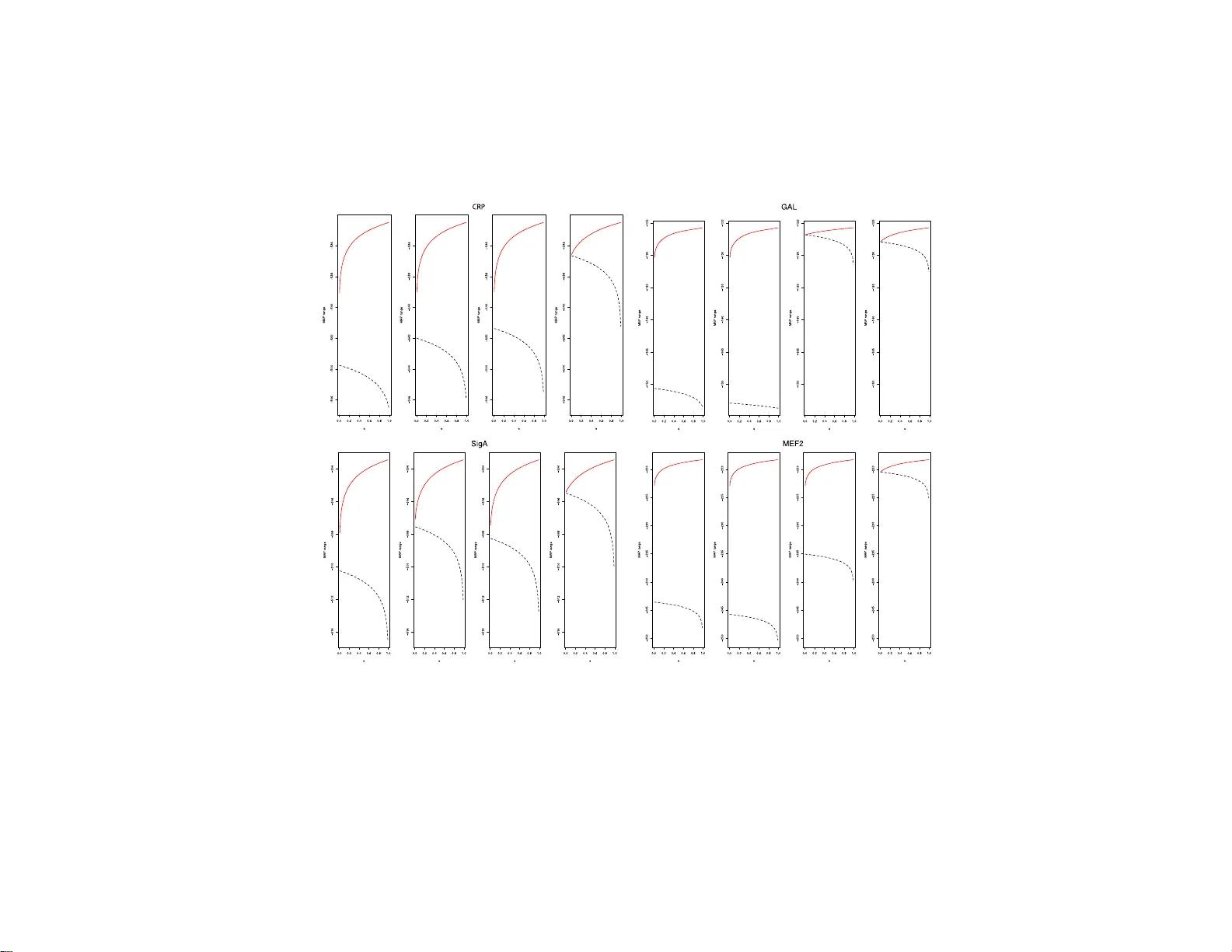
실험에서는 네 개의 실제 데이터셋(yeast CRP, GAL4, B. subtilis σA, 인간 MEF2)에서 MAP 점수와 MAP 발산 인자를 계산하고, 기존의 AIC, BIC, Kullback‑Leibler 정보 기준과 비교하였다. 결과는 특히 모티프 길이가 5 이상일 때 MAP가 다른 기준보다 높은 구별력을 보이며, 가짜 모티프가 없는 데이터에서는 MAP 점수가 배경 모델보다 현저히 낮아 false positive를 효과적으로 억제한다는 점을 강조한다.
마지막으로 사전 하이퍼파라미터 β (배경 사전)와 γ (모티프 사전)에 대한 민감도 분석을 수행했다. β를 1보다 크게, γ를 충분히 큰 값(예: 10)으로 설정하면 MAP 점수의 변동성이 감소하고, 실제 모티프 검출에 대한 강건성이 향상된다. 이는 사전 선택이 모델 선택 결과에 미치는 영향을 정량적으로 평가한 드문 사례이며, 실무 적용 시 중요한 가이드라인을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기