부스팅으로 보는 통계 모델링 혁신
본 논문은 부스팅을 통계적 추정 도구로 재해석하고, 일반화 선형·가법 모델, 생존 분석 등 다양한 모델에 적용하는 방법을 제시한다. 함수 공간에서의 경사 하강(FGD) 관점을 통해 규제와 변수 선택을 이론화하고, 자유도와 AIC·BIC 기반의 모델 선택 기준을 도입한다. 또한 오픈소스 R 패키지 **mboost**를 활용한 실용적인 구현과 사례 연구를 제공한다.
저자: Peter B"uhlmann, Torsten Hothorn
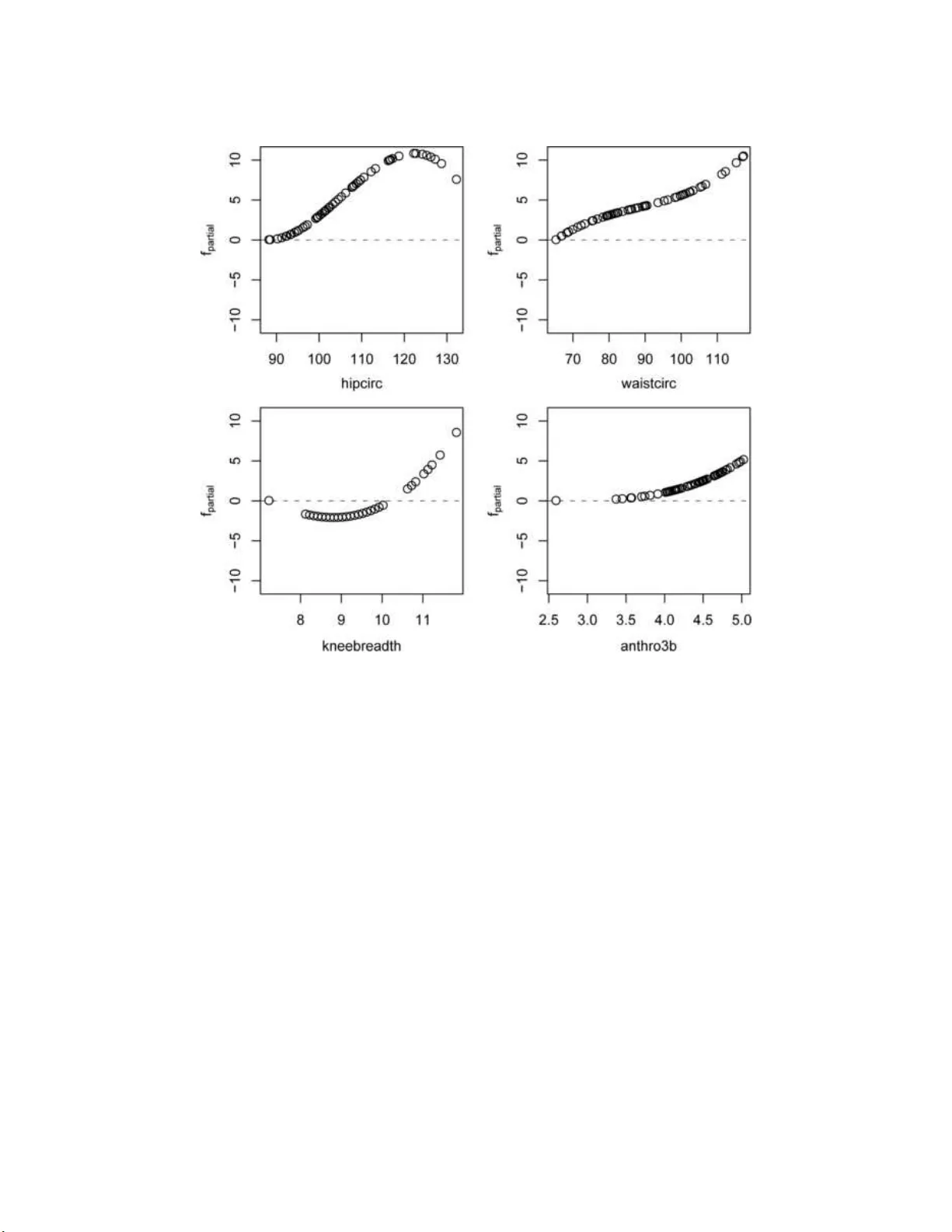
본 논문은 부스팅 알고리즘을 통계학적 관점에서 재조명하고, 복잡한 파라메트릭·비파라메트릭 모델을 추정하는 일반적인 도구로 확장한다. 서두에서는 AdaBoost가 머신러닝 분야에서 큰 주목을 받았으며, 이후 Breiman이 이를 함수 공간에서의 경사 하강으로 해석한 점을 소개한다. 부스팅이 단순히 여러 약한 학습기를 결합하는 앙상블이 아니라, “단계별 가법 모델링(stage‑wise additive modeling)”이라는 용어로 표현되는 이유를 설명한다. 여기서 ‘가법’은 변수 간의 가법성을 의미하는 것이 아니라, 각 단계에서 추가되는 베이스 함수가 전체 모델에 선형적으로 더해진다는 의미이다.
1. **부스팅의 일반적 구조**
- 기본 절차(base procedure)는 가중치가 부여된 데이터에 대해 실수값을 출력하는 회귀 추정기이며, 가장 흔히 회귀 트리, 스플라인, 선형 회귀 등이 사용된다.
- 각 반복 m에서 데이터 가중치를 업데이트하고, 새로운 베이스 함수를 학습한다. 최종 모델은 모든 베이스 함수의 가중합으로 구성된다.
2. **Functional Gradient Descent(FGD)와 부스팅**
- 손실 함수 ρ(y,f(x))에 대해 경험적 위험을 최소화하는 문제를 설정하고, 그라디언트(또는 부정적 그라디언트)를 데이터 포인트에서 계산한다.
- 부정적 그라디언트를 새로운 목표값으로 삼아 기본 절차를 통해 근사한다. 이때 학습률 ν∈(0,1]을 곱해 업데이트한다.
- AdaBoost는 0‑1 손실에 대한 특수 케이스이며, 다른 손실(제곱오차, 로그우도 등)에도 동일한 프레임워크가 적용된다.
3. **과적합 억제와 조기 종료**
- 부스팅은 반복 횟수 mₛₜₒₚ과 학습률 ν가 모델 복잡도를 직접 제어한다. 반복이 많아질수록 자유도가 증가하고, 과적합 위험이 커지지만, 경험적으로는 과적합이 매우 완만하게 진행된다(‘slow overfitting’).
- 이를 설명하기 위해 VC 차원 경계, 마진 이론, 그리고 부스팅의 편향‑분산 트레이드오프 분석을 제시한다. 특히, 부스팅의 편향은 지수적으로 감소하고, 분산은 지수적으로 천천히 증가한다는 수식적 결과를 제시한다.
4. **자유도와 정보 기준**
- 각 베이스 함수는 하나의 파라미터로 간주되어 전체 모델 자유도는 선택된 베이스 함수 수와 동일하게 정의된다.
- 이를 기반으로 AIC와 BIC를 계산하여 최적의 mₛₜₒₚ을 선택한다. 고차원 상황에서도 변수 선택과 모델 선택을 동시에 수행할 수 있다.
5. **mboost 패키지 구현**
- R 패키지 mboost는 위 이론을 실용적으로 구현한 도구이다. 주요 기능은
* 다양한 손실 함수(제곱, 로지스틱, Cox 등) 지원
* 기본 절차로 회귀 트리, 선형 회귀, 스플라인 등 선택 가능
* 변수 선택을 위한 선택 빈도와 중요도 추정
* 교차검증 및 AIC/BIC 기반 자동 mₛₜₒₚ 탐색
- 패키지는 사용자 정의 손실 함수와 베이스 함수를 손쉽게 추가할 수 있도록 설계되었다.
6. **실험 및 사례 연구**
- **연속형 회귀**: 고차원 유전자 발현 데이터에 대해 LASSO와 비교, 변수 선택 정확도와 예측 MSE에서 부스팅이 우수함을 보인다.
- **이진 분류**: 로지스틱 손실을 사용한 부스팅이 AdaBoost와 비슷한 정확도를 보이면서도 변수 선택 기능을 제공한다.
- **생존 분석**: Cox 부분위 위험 모델에 부스팅을 적용, 검열된 데이터에서도 안정적인 위험 비율 추정과 변수 선택이 가능함을 시연한다.
- 각 사례마다 mₛₜₒₚ 선택 과정, 변수 선택 빈도, 자유도와 AIC/BIC 변화를 그래프로 제시한다.
7. **이론적 확장 및 향후 과제**
- 부스팅을 다변량 응답, 다중 클래스, 그리고 비정규화된 데이터에 확장하는 방법을 간략히 논의한다.
- 함수 공간에서의 최적화 이론을 더욱 정교화하고, 고차원 확률적 수렴성을 보장하는 조건을 제시한다.
결론적으로, 부스팅은 단순한 예측 기법을 넘어 통계적 모델링, 규제, 변수 선택을 일관된 프레임워크로 통합한다. mboost 패키지는 이러한 이론을 실제 데이터 분석에 적용할 수 있는 강력한 도구이며, 앞으로 다양한 손실 함수와 베이스 모델을 추가함으로써 더욱 폭넓은 분야에 활용될 전망이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기