클래스 구분성을 한눈에 보는 새로운 혼합 지표
본 논문은 기존의 클래스 구분성 지표인 분리 지수(SI)와 가설 마진(HM)의 한계를 분석하고, SI가 100 %에 도달했을 때 HM을 연계해 연속적인 구분성 값을 제공하는 혼합 지표를 제안한다. 간단한 2‑Gaussian 시뮬레이션을 통해 제안 방법의 유용성을 입증한다.
저자: ** *논문 본문에 저자 정보가 명시되어 있지 않으므로, 저자명은 확인할 수 없습니다.* **
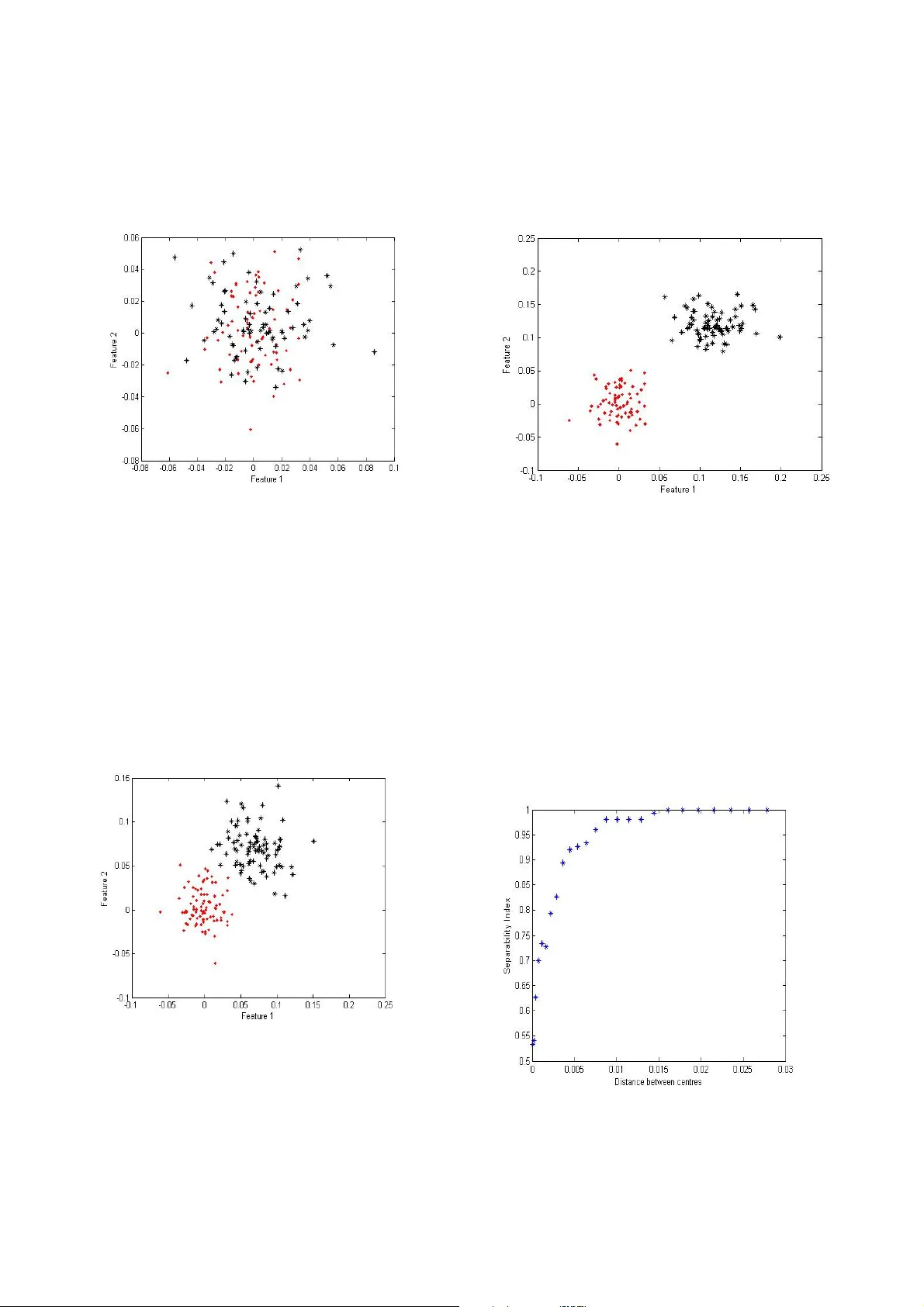
논문은 먼저 클래스 구분성을 정량화하는 필요성을 강조한다. 고차원 데이터에서 시각적으로 클래스 분포를 파악하기 어려운 상황에서, 간단하고 직관적인 지표가 분류기 설계와 피처 선택에 큰 도움이 된다. 기존 연구에서 제안된 두 가지 지표, 즉 분리 지수(SI)와 가설 마진(HM)을 소개하고 각각의 정의와 동작 원리를 설명한다. SI는 각 샘플의 최근접 이웃이 동일 라벨을 갖는 비율을 평균화한 값으로, 0에서 1(또는 0 %~100 %) 사이의 값으로 표현된다. 이 지표는 클래스가 겹쳐 있을 때 민감하게 변하지만, 완전 분리(즉, SI = 1) 상태에 도달하면 더 이상 변화하지 않아 “극단적인 분리 정도”를 측정할 수 없다. 반면 HM은 동일 클래스 내 최근접 이웃(near‑hit)과 이질 클래스 최근접 이웃(near‑miss) 사이의 거리 차이를 누적해 구분성을 측정한다. HM은 클래스 간 거리가 커질수록 값이 계속 증가하므로, 완전 분리 이후에도 거리 확대 정도를 정량화할 수 있다. 그러나 HM은 절대적인 퍼센트 해석이 어려워 직관적인 이해에 한계가 있다.
이러한 상보적 특성을 이용해 저자들은 두 지표를 결합한 혼합 지표를 제안한다. 구체적인 알고리즘은 다음과 같다. 먼저 SI를 계산하고, SI가 1 미만이면 혼합 지표는 100 × SI로 정의한다. SI가 1에 도달하면, 최초로 SI = 1이 된 순간의 HM 값을 기준값(ih)으로 저장하고, 이후 계산되는 HM을 ih 로 나눈 비율(hm_ratio)을 구한다. 최종 혼합 지표는 100 × hm_ratio가 된다. 즉, 초기 단계에서는 인스턴스 겹침 정도를 퍼센트로 직관적으로 보여주고, 완전 분리 이후에는 “SI = 100 % 기준보다 몇 배 더 멀다”는 형태로 거리 확대를 퍼센트 비율로 표현한다.
제안된 방법의 유효성을 검증하기 위해 두 개의 2‑차원 가우시안 클러스터를 사용한 시뮬레이션을 수행한다. 클러스터 중심 간 거리를 점진적으로 증가시키면서 SI와 HM을 각각 측정한다. 결과는 다음과 같다. 초기 겹침 단계에서 SI는 0.54에서 0.98까지 상승하고, 0.015 단위 이상 거리 증가 시 SI는 1.0에 머문다. 반면 HM은 거리 증가에 따라 1.54, 1.96, … 등 지속적으로 상승한다. 혼합 지표는 SI가 1에 도달하기 전까지는 90 %~98 % 수준을 유지하고, 이후 HM 비율을 100배 스케일링해 112 %, 124 %, 137 % 등으로 증가한다. 표 1에 제시된 수치들을 통해 “클래스가 SI = 100 % 기준보다 1.24배 더 멀다”는 직관적인 해석이 가능함을 확인한다.
논문은 이러한 결과를 바탕으로 혼합 지표가 (1) 초기 단계에서 인스턴스 기반 겹침을 명확히 파악하고, (2) 완전 분리 이후에도 거리 기반 정보를 지속적으로 제공함으로써 두 기존 지표의 장점을 모두 보존한다고 주장한다. 또한, 피처 선택이나 차원 축소 과정에서 최적 서브스페이스를 탐색할 때, 이 혼합 지표를 목적 함수로 사용하면 클래스 구분성을 보다 정밀하게 평가할 수 있을 것으로 기대한다. 마지막으로 연구 지원을 남아프리카 공화국 국가연구재단(NRF)으로부터 받았음을 밝히며, 관련 문헌을 인용한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기