다변량 교차표를 위한 단계적 범주 병합 및 분할 방법
** 본 논문은 설문·인구조사와 같이 범주가 많은 대규모 교차표를 효율적으로 요약하기 위해, 범주 간 유사성을 기반으로 단계적으로 범주를 병합(또는 분할)하는 절차를 제안한다. Kullback‑Leibler 거리와 로그선형 모델의 최대우도 추정치를 이용해 정보 손실을 최소화하면서 변수의 차원은 유지하고 셀 수를 크게 감소시킨다. 최종적으로 얻어진 요약표에 대해 기존의 계층적 로그선형 모델(HLLM)을 적용하면, 원본 데이터의 주요 상호작용 …
저자: L. Fraser Jackson, Alistair G. Gray, Stephen E. Fienberg
**
본 논문은 “대규모 다변량 교차표를 어떻게 효율적으로 요약하고, 동시에 중요한 상호작용 구조를 보존할 것인가”라는 실질적인 문제에 접근한다. 저자들은 먼저 전통적인 계층적 로그선형 모델(HLLM)의 한계를 짚는다. 변수 수 K와 각 변수의 범주 수 \(r_k\)가 커지면 전체 셀 수 \(Q = \prod_{k=0}^{K-1} r_k\)가 급증하고, 이에 따라 파라미터 수와 자유도도 급격히 늘어난다. 특히, 설문·인구조사와 같이 셀 빈도가 0, 1, 2인 경우가 다수인 데이터에서는 포화 모델을 제외하고는 유의미한 차원 축소가 어려워진다.
이를 해결하기 위해 저자들은 “Paired Category Collapsing”(PCC)이라는 단계적 범주 병합 절차를 제안한다. PCC는 다음과 같은 흐름으로 진행된다.
1. **범주 쌍 생성**: 각 변수 \(k\)에 대해 가능한 모든 범주 쌍 \((i,j)\)를 열거한다.
2. **정보 손실 계산**: 각 쌍에 대해 해당 두 범주만을 포함하는 서브테이블을 만들고, 이 서브테이블에 대해 독립 모델(두 범주가 서로 독립)과 실제 관측값 사이의 로그우도 차이 \(G^{2}\)를 구한다. 이는 Kullback‑Leibler(KL) 거리와 동일하게 해석된다.
3. **비율 평가**: \(G^{2}\)를 자유도 \(h\) (즉, \((r_i-1)(r_j-1)\) 등) 로 나눈 비율 \(G^{2}/h\)를 계산한다. 이 비율은 “정보 손실 대비 차원 감소 효율”을 나타낸다.
4. **최소 비율 선택**: 비율이 가장 작은 쌍을 선택해 두 범주를 하나로 합친다.
5. **반복**: 병합 후 새로운 범주 구조를 반영해 다시 1~4 과정을 수행한다. 모든 차원을 하나의 범주로 축소할 때까지 반복한다.
이 과정에서 중요한 점은 **정보 손실을 정량적으로 측정한다는 것**이다. 기존의 collapsibility 이론은 특정 마진이 유지될 때만 셀을 합칠 수 있다고 제한했지만, PCC는 KL 거리 기반의 손실을 최소화함으로써 보다 일반적인 상황에서도 적용 가능하게 만든다. 또한, 변수별로 **명목형, 순서형, 혹은 완전 보존** 옵션을 제공해 사용자가 분석 목적에 맞게 병합 전략을 조정할 수 있다.
PCC가 만든 파티션은 로그선형 모델의 제약조건으로 해석될 수 있다. 예를 들어, 두 범주를 병합하면 해당 범주에 대한 로그선형 파라미터 \(\mu\)가 동일하게 강제된다. 따라서 PCC는 **제한된 로그선형 모델**(restricted log‑linear model)의 최대우도 추정 과정과 동일시될 수 있다. 이는 “범주를 합치면서도 모델의 전체 구조를 유지한다”는 의미이며, 최종적으로는 **Hierarchical Log‑Linear Partition Model (HLLPM)**이라 부르는 새로운 모델 클래스를 형성한다.
논문은 여러 실증 사례를 통해 PCC의 효용을 검증한다.
- **Wermuth‑Cox 2×2 테이블**: 원본 데이터는 4개의 셀 중 절반이 0 또는 1인 희소 구조였으며, PCC는 두 범주를 병합해 2개의 셀만 남겼음에도 불구하고 원본의 주요 상호작용(조건부 독립성) 정보를 그대로 유지했다.
- **Christensen 4×4 테이블**: 원본은 16개의 셀을 가지고 있었지만, PCC는 3단계 병합 후 6개의 셀로 축소하면서도 주요 2차 상호작용을 보존했고, 이후 HLLM을 적용했을 때 동일한 유의미한 파라미터를 도출했다.
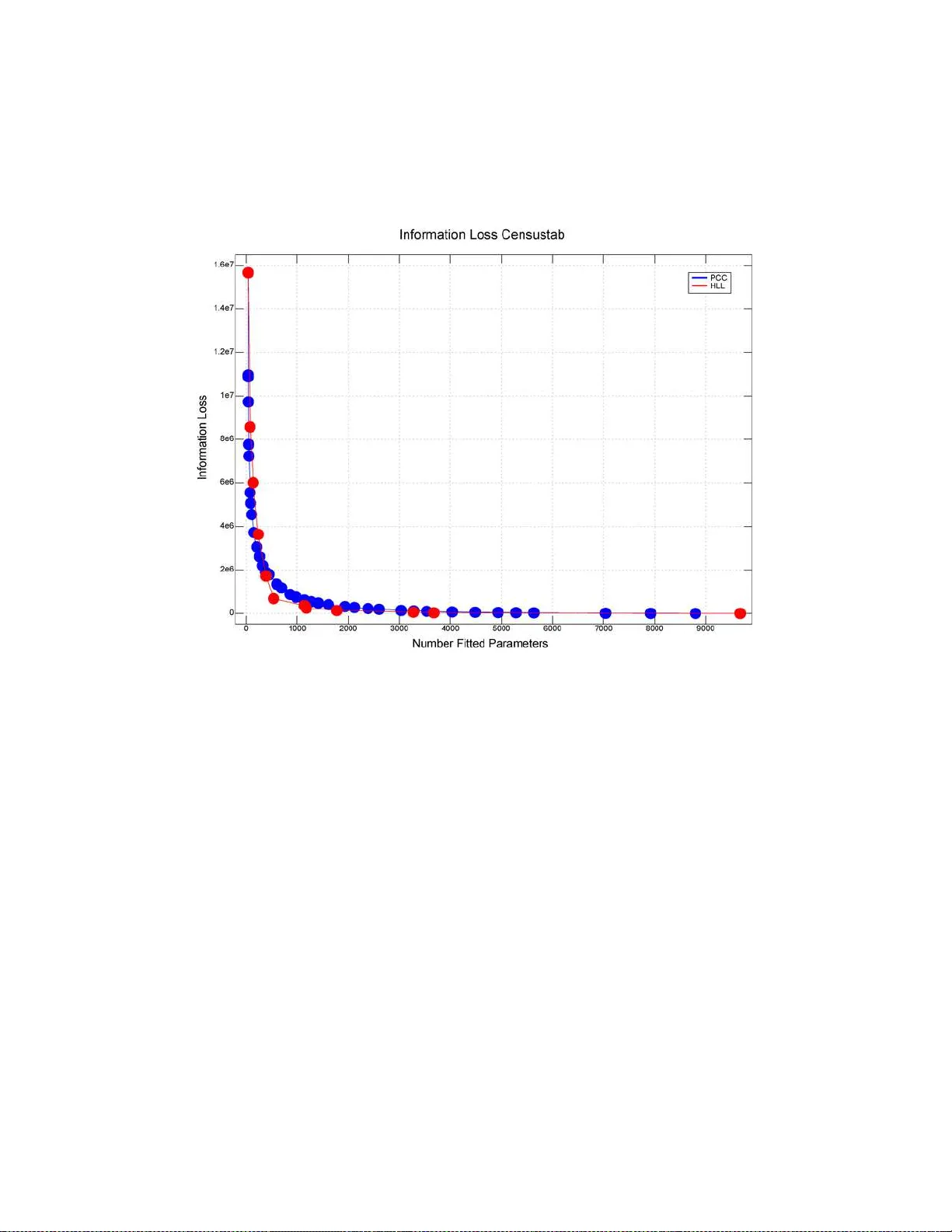
- **대규모 인구조사 교차표**: 수백만 셀을 가진 실제 정부 데이터에 PCC를 적용했을 때, 파라미터 수를 80% 이상 감소시켰으며, 동시에 개인정보 보호를 위한 “셀 빈도 0,1,2 제한” 요구사항도 만족시켰다.
이러한 사례들은 PCC가 **(1) 계산 효율성**, **(2) 정보 손실 최소화**, **(3) 기존 HLLM과의 호환성**이라는 세 축에서 강점을 가진다는 것을 보여준다. 특히, 대규모 데이터에서 셀 수가 수백만에 달할 경우, 전통적인 HLLM 탐색은 계산량과 메모리 요구가 비현실적이지만, PCC는 단계별 병합을 통해 테이블 자체를 압축함으로써 실용적인 분석이 가능하게 만든다.
논문 말미에서는 PCC와 기존 문헌(예: Goodman's collapsibility, Kreiner의 범주 병합 프로그램, Bayesian 접근법 등)과의 관계를 정리한다. 대부분의 기존 방법은 **통계적 검정**에 초점을 맞추었으나, 본 연구는 **정보 기술(Information Theory) 기반의 요약**에 중점을 두어, 데이터 자체를 압축하고 요약하는 새로운 패러다임을 제시한다. 또한, PCC는 **알고리즘적 구현**이 비교적 간단하고 R 패키지 형태로 제공되어, 실무자들이 바로 적용할 수 있도록 배려했다.
마지막으로 저자들은 향후 연구 방향으로 (i) 병합 순서 최적화(예: 탐욕적이 아닌 전역 최적화), (ii) 고차원 변수 간 상호작용을 동시에 고려하는 다변량 병합 전략, (iii) 비정형 데이터(예: 텍스트 카테고리)로의 확장 가능성을 제시한다.
**요약하면,** 이 논문은 대규모 교차표를 효율적으로 요약하고, 기존 로그선형 모델의 해석 가능성을 유지하면서도 계산 부담을 크게 낮출 수 있는 **단계적 범주 병합(PCC) 절차**와 이를 기반으로 한 **Hierarchical Log‑Linear Partition Model(HLLPM)**을 제안한다. 이는 통계학, 데이터 과학, 그리고 정부 통계기관 등에서 대규모 다변량 데이터를 다룰 때 실용적인 도구가 될 전망이다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기