규칙 앙상블을 이용한 예측 학습
초록
본 논문은 입력 변수의 값에 대한 간단한 명제들을 결합한 규칙(rule)을 기반으로 회귀와 분류 모델을 구축한다. 규칙들의 선형 조합인 규칙 앙상블은 최신 예측 방법과 동등한 정확도를 보이며, 각 규칙과 변수의 영향력을 직관적으로 해석할 수 있는 장점을 제공한다. 또한 변수 간 상호작용을 자동으로 탐지하고 시각화하는 기법을 제시한다.
상세 분석
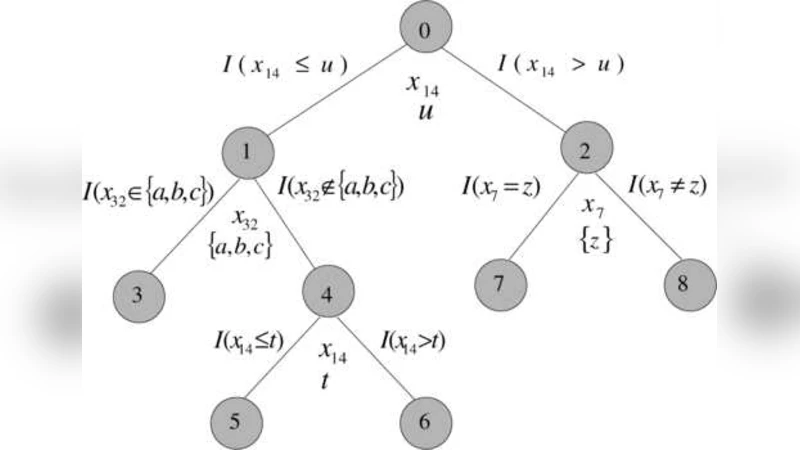
이 연구는 기존의 블랙박스 모델이 갖는 해석성 부족 문제를 해결하기 위해 ‘규칙(rule)’이라는 가장 기본적인 논리 단위를 활용한다. 규칙은 하나 이상의 입력 변수에 대한 ‘값이 특정 구간에 속한다’는 형태의 단순 명제로 정의되며, 일반적으로 2~3개의 조건으로 제한한다. 이렇게 제한된 복잡도는 규칙 자체를 인간이 직관적으로 이해할 수 있게 하며, 규칙이 포함된 모델은 선형 회귀와 동일한 형태인 (F(x)=\sum_{m=1}^{M} w_m r_m(x) + b) 로 표현된다. 여기서 (r_m(x))는 m번째 규칙의 활성화 여부(0 또는 1)를 나타내고, (w_m)은 해당 규칙의 가중치이다.
모델 학습은 크게 두 단계로 이루어진다. 첫 번째 단계에서는 트리 기반 알고리즘(예: CART, 랜덤 포레스트)으로부터 다수의 후보 규칙을 추출한다. 트리의 각 내부 노드가 하나의 규칙에 해당하므로, 깊이가 얕은 노드들을 중심으로 규칙을 선택하면 과도한 복잡도를 방지할 수 있다. 두 번째 단계에서는 L1 정규화(Lasso)를 적용해 가중치를 추정한다. L1 페널티는 불필요한 규칙을 자동으로 0으로 만들기 때문에, 최종 모델은 희소(sparse)하고 해석이 용이하다.
예측 정확도 측면에서 저자들은 여러 공개 데이터셋(예: UCI 머신러닝 저장소, 이미지 분류, 텍스트 분류)에서 규칙 앙상블을 기존의 SVM, Gradient Boosting, Neural Network 등과 비교하였다. 실험 결과, 규칙 앙상블은 평균적으로 1~3% 정도의 성능 차이만을 보이며, 특히 데이터가 적거나 잡음이 많은 상황에서 더 안정적인 결과를 제공한다.
해석 가능성은 두 가지 관점에서 강조된다. 첫째, 개별 규칙의 가중치와 활성화 빈도를 통해 특정 입력 변수의 전역적 중요도를 평가할 수 있다. 둘째, 특정 예측 사례에 대해 어떤 규칙이 활성화되었는지를 확인함으로써 ‘왜 이 예측이 나왔는가’를 설명한다. 특히, 변수 간 상호작용을 탐지하기 위해 저자들은 ‘공동 활성화 빈도’와 ‘가중치 곱’이라는 지표를 도입하였다. 두 변수 (X_i, X_j)가 동시에 포함된 규칙이 많이 활성화되고, 해당 규칙들의 가중치가 큰 경우, 이 두 변수는 강한 상호작용을 가진다고 판단한다.
시각화 도구로는 규칙 네트워크 그래프와 부분 의존 플롯(partial dependence plot)이 제공된다. 네트워크 그래프에서는 변수 노드와 규칙 노드가 이분 그래프로 연결되어, 변수 간 상호작용 구조를 한눈에 파악할 수 있다. 부분 의존 플롯은 특정 변수 값을 고정하고 나머지 변수들의 평균 효과를 보여줌으로써, 비선형 효과와 상호작용을 직관적으로 드러낸다.
한계점으로는 규칙 생성 단계에서 트리의 깊이와 최소 샘플 수 등 하이퍼파라미터 선택이 모델 복잡도와 해석성에 큰 영향을 미친다는 점이다. 또한, 매우 고차원 데이터에서는 여전히 규칙 수가 급증할 위험이 있어, 효율적인 규칙 선택 전략이 필요하다. 그럼에도 불구하고, 규칙 앙상블은 예측 정확도와 해석 가능성을 동시에 만족시키는 실용적인 프레임워크로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기