멀티코어 시대의 흐름과 과제
초록
**
본 논문은 전통적인 클럭 주파수 상승이 물리적 한계에 봉착함에 따라 다코어(CMP) 설계가 주류가 된 현상을 조명한다. 하드웨어 수준의 병렬성(슈퍼스칼라, SMT, CMP)과 소프트웨어 수준의 병렬성(프로그래밍 모델, 컴파일러, OS) 사이의 격차를 분석하고, 40년간 축적된 병렬 컴퓨팅 연구를 재활용해야 함을 주장한다. 또한, 하드웨어 구조 표현의 표준화와 도메인 특화 병렬화 전략 두 축을 미래 연구의 핵심으로 제시한다.
**
상세 분석
**
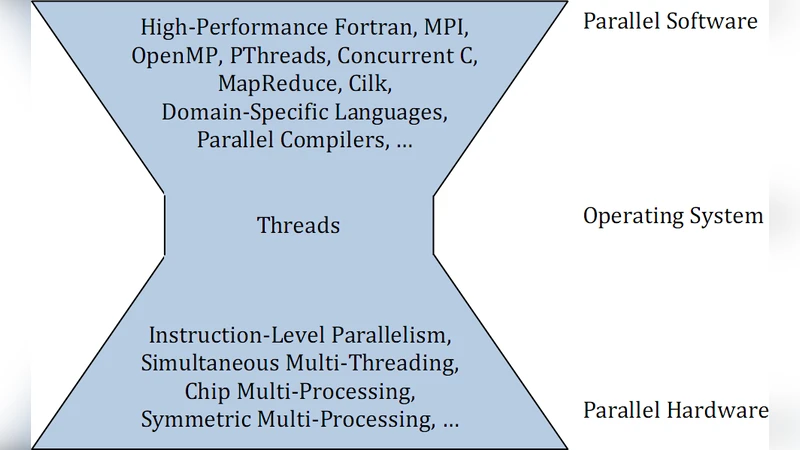
논문은 먼저 1995년 피스터가 제시한 “더 열심히 일하라, 더 똑똑하게 일하라, 도움을 받아라”라는 세 가지 가속 원칙을 현대 멀티코어 환경에 재해석한다. 전통적인 클럭 주파수와 트랜지스터 밀도 증가가 냉각·전력 한계에 부딪히면서, 제조업체들은 이제 추가 트랜지스터를 코어 수 확대에 활용하고 있다. 이는 MIMM(다중 명령·다중 데이터) 형태의 진정한 병렬 기계, 즉 CMP를 만들게 된다.
하드웨어 차원에서는 슈퍼스칼라·SMT·CMT와 같은 미세 수준의 병렬성부터, 수천 개 코어를 메쉬 혹은 타일 구조로 연결하는 대규모 CMP까지 다양한 설계가 존재한다. 동질적 다코어(예: Intel Xeon, TILE64)와 이종 다코어(예: IBM Cell, zSeries) 사이의 트레이드오프를 논의하며, 특히 메모리·I/O 대역폭 병목과 캐시 일관성 문제가 스케일링을 저해한다는 점을 강조한다. 기존의 INMOS 트랜스퍼, 벡터 컴퓨터, MPP와 같은 과거 아키텍처가 제공하는 교훈을 재활용할 필요성을 제시한다.
소프트웨어 차원에서는 기존의 순차적 프로그래밍 패러다임이 더 이상 유효하지 않으며, 개발자는 초기에 병렬성을 고려해야 한다는 교육·문화적 변화를 요구한다. Amdahl 법칙과 Gustafson 법칙을 통해 병렬화 한계와 문제 규모 확대에 따른 효율성을 설명하고, 자동 병렬화 컴파일러, OS 스케줄러, 라이브러리(OpenMP, Cilk, MapReduce 등)의 현재 한계와 향후 연구 과제를 제시한다. 특히, 스레드 기반 모델이 여전히 주류이지만, 데이터 병렬, 함수형, 반응형 프로그래밍 등 대안 모델이 필요함을 강조한다.
핵심적인 통찰은 “하드웨어 구조를 추상화하고, 도메인 특화 병렬화 전략을 설계하라”는 두 축이다. 기존의 병렬 알고리즘·스케줄링 이론을 현대의 수천 코어 환경에 맞게 재정의하고, 현실적인 메모리·캐시·네트워크 특성을 반영한 새로운 모델(LogP, BSP, PRAM의 확장)을 개발해야 한다는 점을 강조한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기