알파벳 최소 최대 트리 구축을 위한 새로운 알고리즘
이 논문은 실수 가중치 배열 W에 대해 알파벳 순서를 유지하면서 최대 wi+ℓi 값을 최소화하는 이진 알파벳 최소‑최대 트리를 O(nd log log n) 시간에 구축하는 알고리즘을 제시한다. 여기서 d는 ⌈wi⌉ 의 서로 다른 정수값 개수이며, 제안 기법은 기존 O(n log n) 알고리즘을 개선한다. 또한 샘플 분포를 이용한 알파벳 프리픽스 코드 설계에도 적용 가능함을 보인다.
저자: Travis Gagie
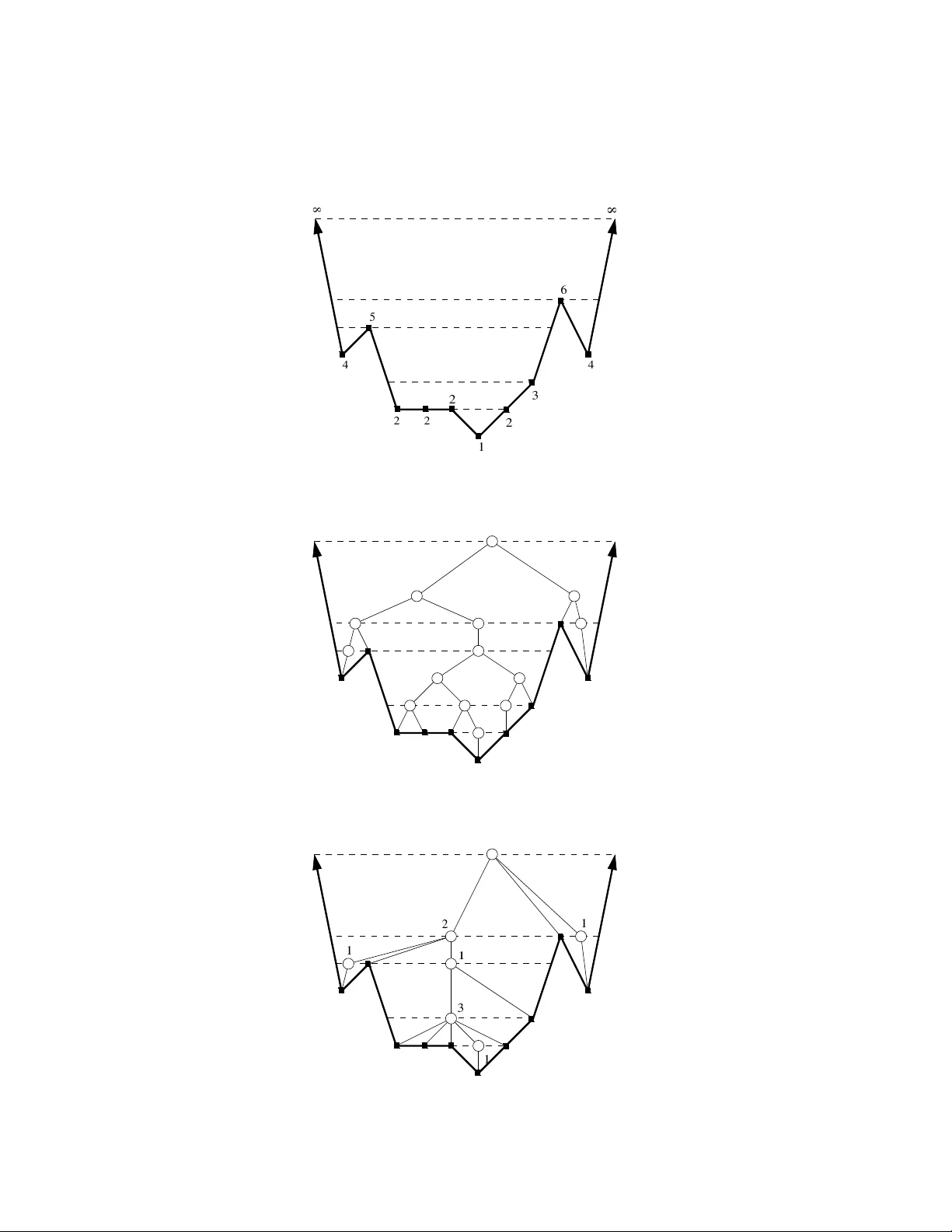
논문은 알파벳 최소‑최대 트리(Alphabetic Minimax Tree) 문제를 다루며, 입력으로 실수 가중치 배열 W=(w₁,…,wₙ)과 정수 t≥2(논문에서는 t=2, 즉 이진 트리)를 받는다. 목표는 리프들의 왼‑오른 순서를 유지하면서 각 리프 i 의 깊이 ℓᵢ와 가중치 wᵢ의 합 wᵢ+ℓᵢ 의 최댓값을 최소화하는 트리를 찾는 것이다. 기존 연구에서는 Hu·Kleitman·Tamaki가 O(n log n) 알고리즘을, Kirkpatrick·Klawe가 정수 가중치에 대해 O(n)·O(n log n) 알고리즘을 제시했으며, 병렬·프리픽스 코드 응용도 있었다. 그러나 실수 가중치에 대해 O(n log n)보다 빠른 방법은 없었다.
본 논문은 두 가지 주요 개선점을 제시한다. 첫 번째는 가중치의 소수부 bᵢ = wᵢ−⌊wᵢ⌋ 를 정렬 없이 탐색하는 방법이다. Kirkpatrick·Klawe는 “α(⌈w₁−bᵢ⌉,…,⌈wₙ−bᵢ⌉) = α(⌈w₁−bₙ⌉,…,⌈wₙ−bₙ⌉) ⇔ i 가 최소”라는 성질을 이용해 이진 탐색을 수행했지만, 매 단계마다 전체 트리를 재구성해야 했다. 저자는 이를 개선하기 위해 Blum·et·al.의 선형 선택 알고리즘을 사용해 현재 후보 집합 Sₖ 의 중간값 mₖ를 O(n) 시간에 찾고, 이를 기준으로 집합을 세 부분 S′ₖ, S″ₖ, S‴ₖ 로 나눈다. 이후 mₖ 보다 작은 bᵢ에 대해 set(i) 연산을 수행하고, 현재 트리의 비용 α를 cost 연산으로 확인한다. 이 과정을 반복하면서 후보 구간을 반으로 좁혀 가며, 최종적으로 최소 bᵢ 를 찾는다.
두 번째 핵심은 레벨 트리(level tree)라는 데이터 구조를 도입한 것이다. 레벨 트리는 가중치 배열 Y = (⌈w₁⌉−x₁,…,⌈wₙ⌉−xₙ) 에 대해 평면에 점 (i, yᵢ)를 연결한 다각형 선을 그리고, 각 구간을 “레벨 인터벌”로 정의한다. 이 인터벌들을 노드로 하는 트리를 만들면, 트리의 루트 가중치가 바로 α(Y)와 일치한다. 중요한 점은 한 리프의 xᵢ 값을 1로 바꾸면(즉 yᵢ 를 1 감소시키면) 영향을 받는 경로가 d (서로 다른 정수 가중치 개수) 이하라는 점이다. 따라서 set, undo, cost 연산을 레벨 트리와 union‑find 구조를 결합해 O(d log log n) 시간에 처리할 수 있다.
구체적인 알고리즘 흐름은 다음과 같다.
1. bₙ = maxᵢ bᵢ 를 구하고, ⌈wᵢ−bₙ⌉ 에 대해 Kirkpatrick·Klawe의 O(n) 알고리즘으로 초기 비용 α₀을 얻는다.
2. S₀ = {bᵢ} 를 멀티셋으로 두고, 현재 집합 Sₖ 에 대해 중간값 mₖ를 선형 선택으로 찾는다.
3. mₖ보다 작은 bᵢ에 대해 set(i) 연산을 수행하고, 레벨 트리의 cost 연산으로 현재 α를 계산한다.
4. α가 α₀와 같으면 mₖ은 후보이며, 그렇지 않으면 Sₖ 을 S′ₖ 또는 S‴ₖ 로 교체한다(이진 탐색과 동일한 효과).
5. 각 단계에서 수행되는 set, undo, cost 연산은 레벨 트리와 union‑find를 이용해 O(d log log n) 시간에 처리한다.
6. 전체 O(n) 단계가 끝나면 최적 bᵢ 를 찾게 되고, 해당 ⌈wᵢ−bᵢ⌉ 에 대해 Kirkpatrick·Klawe의 O(n) 알고리즘을 한 번 더 실행해 최종 알파벳 최소‑최대 트리를 만든다.
시간 복잡도 분석에서는 각 단계에서 중간값 찾기와 집합 분할이 O(n/2ᵏ) 시간에 수행되고, 전체 단계에 걸쳐 O(n) 시간이 소요된다. 레벨 트리 연산은 전체 O(nd) 번 발생하고, union‑find의 역전 연산이 O(nd log log n) 시간을 차지한다. 따라서 최종 복잡도는 O(nd log log n)이다.
알고리즘의 장점은 d 가 작을 경우(예: 로그 확률값이 거의 동일하거나 정수부 차이가 제한적인 경우) O(n log log n) 시간에 해결 가능하다는 점이다. 또한 d 가 n 에 가까워도 기존 O(n log n) 알고리즘과 동일한 차원에서 동작한다. 논문은 이 방법을 알파벳 프리픽스 코드 설계에 적용한다. 샘플 분포 Q의 로그값 log qᵢ 를 가중치로 사용하면, 최적 코드는 바로 log qᵢ 에 대한 알파벳 최소‑최대 트리와 동일하므로, 제안 알고리즘을 사용해 샘플이 정렬되지 않은 경우에도 O(n log log n) 시간에 코드를 생성할 수 있다.
마지막으로 논문은 무순서(minimax) 트리와의 관계를 언급하며, Drmota·Szpankowski와 Golumbic의 연구를 인용해 Huffman‑유사 알고리즘이 무순서 최소‑최대 트리를 O(n log n) 혹은 정렬된 경우 O(n) 시간에 구축할 수 있음을 보인다. 저자는 블룸의 선택 알고리즘을 활용하면 정렬되지 않은 경우에도 O(n) 시간에 가능할 것으로 추측한다.
결론적으로, 이 논문은 알파벳 최소‑최대 트리 문제에 대해 기존 O(n log n) 한계를 깨고, 가중치의 정수부 다양성 d 에 따라 O(nd log log n) 혹은 O(n min(d log log n, log n)) 시간으로 해결하는 새로운 알고리즘을 제시한다. 이는 데이터 압축, 검색 트리 재구성, 그리고 확률 기반 코딩 등 다양한 응용 분야에 실질적인 성능 향상을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기