소표본·고복잡도 상황에서의 모델 선택과 예측 성능 평가
본 논문은 표본 크기가 데이터 생성 과정의 복잡도에 비해 작고 후보 모델 수가 표본보다 훨씬 많은 상황에서, 외삽 예측을 최적화하는 모델 선택 방법을 탐구한다. 유한표본에 대한 명시적 결과를 바탕으로 일반화 교차검증(GCV)과 Tukey의 Sp 준칙이 높은 확률로 좋은 모델을 찾아낸다는 것을 증명하고, AIC·BIC·FPE 등 전통적 기준은 복잡한 모델에 대해 불안정하거나 심각히 잘못된 선택을 할 수 있음을 보인다. 시뮬레이션을 통해 이론적 결…
저자: ** Hannes Leeb (Department of Statistics, Yale University) **
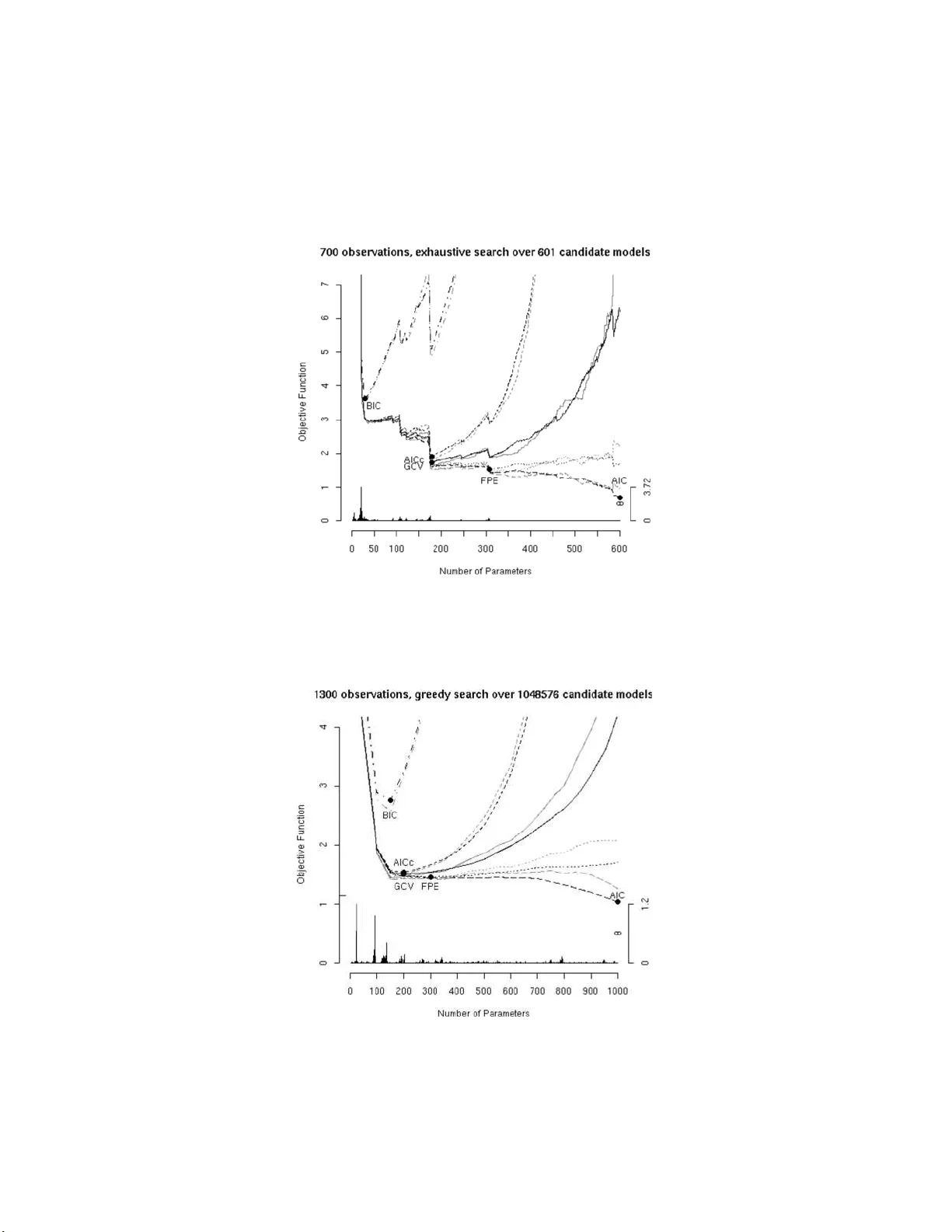
본 논문은 표본 크기 n이 데이터 생성 과정의 복잡도에 비해 작고, 후보 모델의 수가 n보다 훨씬 큰 상황에서 외삽 예측 성능을 최적화하는 모델 선택 문제를 다룬다. 저자는 먼저 기존 모델 선택 기준(AIC, BIC, Cp, FPE 등)이 대다수 경우 큰 표본을 전제로 asymptotic 효율성을 논의했지만, 실제 연구 현장에서는 유전학·생물정보학 등에서 변수 수가 수천에 달하고 표본은 수십~수백 수준인 경우가 빈번함을 지적한다. 따라서 “좋은” 모델의 파라미터 수 |m|이 n과 같은 차수(O(n))에 놓이는 경우를 중심으로 분석을 전개한다.
논문의 구조는 다음과 같다. 1절에서는 문제 설정과 기존 방법론을 소개하고, 2절에서는 사용될 위험 함수 ρ²(m)와 이를 추정하기 위한 GCV(m), Sp(m), 그리고 보조 추정량 ˆρ²(m)을 정의한다. 3절에서는 Gaussian 가정 하에 유한표본에 대한 명시적 경계를 제시한다. 3.1절에서는 보조 추정량 ˆρ²(m)의 편향·분산 특성을 분석하고, 3.2절에서는 GCV와 Sp가 ρ²(m)를 고확률로, 그리고 거의 균일하게(모델 군 전체와 파라미터 공간 전역에 대해) 근사한다는 정리를 제시한다. 핵심 결과는 Theorem 3.4와 Corollary 3.5로, #𝓜ₙ이 지수적으로 커도 (예: 10⁶개) 확률적 보장이 유지된다는 점이다. 증명은 Breiman–Freedman의 대규모 행렬 결과와 Marčenko–Pastur 법칙을 활용해, 설계 행렬의 스펙트럼이 복잡해도 추정 오차가 √(log #𝓜ₙ / n) 수준으로 수렴함을 보인다.
3.3절에서는 전통적 AIC·AICc·FPE·BIC가 동일한 설정에서 체계적으로 결함이 있음을 보여준다. 특히 AIC·Cp는 설계 분포가 알려지지 않은 경우 위험과의 일치도가 급격히 악화되며, 파라미터 구성에 따라 과소·과대 선택이 발생한다. BIC는 일관성을 유지하지만, 위험이 무한대로 발산할 위험이 존재한다는 점을 강조한다.
4절에서는 시뮬레이션 연구를 통해 이론적 결과를 실증한다. n=1,300인 데이터에서 10⁶개의 후보 모델을 대상으로 GCV와 Sp가 일관되게 낮은 외삽 평균제곱오차를 기록했으며, 비정규(heavy‑tailed) 오류와 상관 구조가 있는 경우에도 성능 저하가 미미했다. 반면 AIC·BIC·FPE는 파라미터 설정에 따라 과소·과대 선택을 반복했고, 후보 모델 수가 n에 비해 크게 늘어날수록 선택 불안정성이 심화되었다. 이러한 실험 결과는 고차원·소표본 상황에서 교차검증 기반 방법이 보다 신뢰할 수 있음을 뒷받침한다.
마지막으로 5절에서는 연구의 한계와 향후 과제를 논의한다. 현재 분석은 Gaussian 오류와 선형 회귀 모델에 국한되었으며, 비선형·비정규 상황에 대한 일반화는 추가 연구가 필요하다. 또한, 설계 분포를 완전히 알 수 없는 경우에도 GCV·Sp가 강건함을 보였지만, 설계 변수의 의존 구조가 매우 복잡할 때는 추가적인 보정이 요구될 수 있다. 그럼에도 불구하고, 이 논문은 “표본이 작고 모델 복잡도가 높은” 현실적인 데이터 분석 시나리오에 맞춘 새로운 이론적 프레임워크와 실용적인 지침을 제공한다는 점에서, 고차원 통계학·머신러닝·유전체 데이터 분석 분야에 중요한 기여를 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기