스프레드시트 분석 입문
초록
본 논문은 스프레드시트 모델을 활용한 분석 절차와 용어 정의, 사전 준비 단계, 민감도 분석·토네이도 차트·목표값 탐색 등 기본 기법을 엑셀 내장 기능과 전용 애드인으로 자동화하는 방법을 제시한다. 또한 최적화와 몬테카를로 시뮬레이션의 개념을 간략히 소개하고, 실증 연구 필요성과 향후 애드인 설계 방향을 제언한다.
상세 분석
논문은 먼저 “스프레드시트 분석”이라는 용어를 정의하고, 이를 기존의 재무 모델링·시뮬레이션과 구분한다. 핵심은 모델이 “분석 친화적”이 되도록 구조화하는데, 이를 위해 입력·계산·출력 영역을 명확히 구분하고, 셀 주소가 고정된 네임드 레인지와 일관된 수식 표기법을 사용하도록 권고한다. 이러한 사전 작업은 이후 민감도 분석과 목표값 탐색 시 오류를 최소화하고, 자동화 매크로 작성 시 가독성을 높인다.
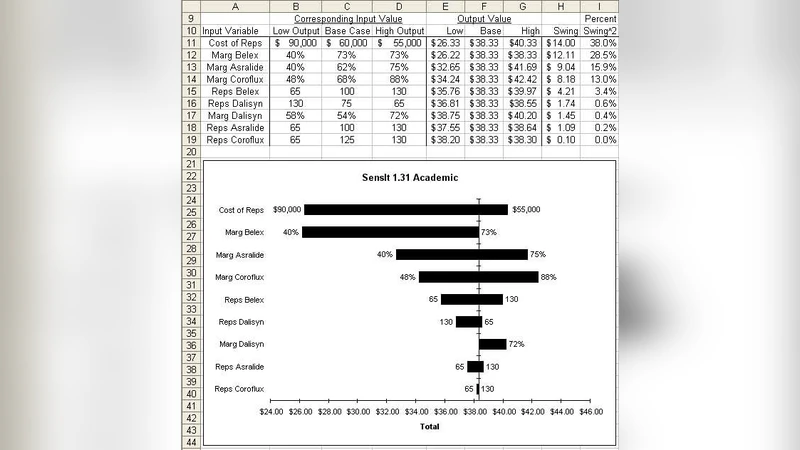
민감도 분석 파트에서는 단일 변수 변화에 따른 결과 변동을 표와 그래프로 시각화하는 절차를 상세히 설명한다. 엑셀의 데이터 테이블(Data Table) 기능을 활용해 다중 시나리오를 한 번에 생성하고, 이를 토네이도 차트로 변환해 변수별 영향력을 직관적으로 비교한다. 토네이도 차트 제작 시에는 정렬된 막대와 색상 코딩을 통해 가장 민감한 인자를 빠르게 식별할 수 있다.
목표값 탐색(Back‑solving, Goal Seek)은 특정 결과값을 달성하기 위해 입력값을 역산하는 기법이다. 논문은 기본 Goal Seek 사용법을 넘어, 복수 변수에 대한 목표값을 동시에 만족시키는 Solver 애드인의 설정 방법을 제시한다. 여기서는 목표 함수 정의, 제약조건 설정, 최적화 알고리즘(선형, 비선형, 정수) 선택 과정을 단계별로 안내한다.
최적화 섹션에서는 비용 최소화·수익 최대화 등 전형적인 목적함수를 정의하고, Solver를 이용한 전역 최적화와 지역 최적화의 차이를 설명한다. 특히, 초기값 선택이 결과에 미치는 영향을 강조하며, 다중 시작점 기법을 통해 전역 최적해에 도달하는 전략을 제시한다.
몬테카를로 시뮬레이션 파트는 확률적 입력 변수에 대해 수천 번의 반복 시뮬레이션을 수행해 결과 분포를 추정하는 방법을 다룬다. 엑셀의 RAND 함수와 데이터 테이블을 결합하거나, @RISK·Crystal Ball 같은 전용 애드인을 활용해 시뮬레이션 모델을 구축한다. 결과 분석에서는 히스토그램, 누적 분포 함수, 민감도(스피어맨) 차트를 통해 위험 요인을 정량화한다.
마지막으로 논문은 현재 상용 애드인들의 한계—예를 들어, 사용자 인터페이스 복잡성, 대규모 데이터 처리 속도 저하, 재현성 보장 부족—를 지적하고, 향후 연구에서는 실증 데이터를 기반으로 한 성능 평가와, 클라우드 기반 협업 기능, 자동 버전 관리 등을 포함한 통합 플랫폼 개발을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기