MIMO 신호 검출을 위한 리스트 크기 제한 다익스트라 알고리즘
** 본 논문은 QR 분해 후 리스트 크기를 제한한 다익스트라 알고리즘을 제안하여, 기존 QRD‑MLD와 그 개선형 대비 동일한 SER을 유지하면서 평균 연산 복잡도를 크게 낮출 수 있음을 실험적으로 입증한다. **
저자: ** - Atsushi Okawado (오카와도 아츠시) – 도쿄공업대학 통신·통합시스템학부 - Ryutaroh Matsumoto (마쓰모토 류타로) – 도쿄공업대학 통신·통합시스템학부 - Tomohiko Uyematsu (우에마쓰 토모히코) – 도쿄공업대학 통신·통합시스템학부 **
**
본 논문은 다중 입력‑다중 출력(MIMO) 통신 시스템에서 최대우도(ML) 검출이 갖는 계산 복잡도 문제를 해결하기 위해, QR 분해 후 리스트 크기를 제한한 다익스트라 알고리즘을 제안한다. 먼저, 시스템 모델을 정의한다. 전송 안테나 수 t와 수신 안테나 수 r( r ≥ t )를 갖는 MIMO 채널을 y = Hx + z 로 표현하고, 수신 측에서 채널 행렬 H를 완벽히 알고 있다고 가정한다. ML 검출은 y와 Hx 사이의 유클리드 거리 ‖y‑Hx‖² 를 최소화하는 x̂ 를 찾는 문제이며, 이는 복소수 연산이 많아 직접 구현 시 지수적 복잡도가 발생한다.
이를 해결하기 위해 QR 분해를 적용한다. H = QR 로 분해하면, 유니터리 행렬 Q는 거리 변환에 영향을 주지 않으므로, ‖y‑Hx‖² = ‖ξ‑Rx‖² (ξ = Q* y) 로 변환된다. 상삼각 행렬 R을 이용해 각 레이어 j에서의 부분 거리 m_j 를 정의하고, 누적 거리 E_j = ∑_{i≤j} m_i 로 표현한다. 이렇게 하면 ML 검출은 루트에서 리프까지의 누적 거리를 최소화하는 경로 탐색 문제와 동등해진다.
기존의 근접 ML 검출 방법으로는 QRD‑MLD와 그 개선형이 있다. QRD‑MLD는 레이어‑별로 누적 거리가 가장 작은 M개의 노드만을 보존하고, 나머지는 버린다. 이는 탐색 공간을 크게 축소하지만, 고정된 M 때문에 SNR에 따라 과도한 후보가 남거나, 반대로 성능 저하가 발생할 수 있다. 개선형 QRD‑MLD는 각 레이어에 임계값 Δ_i = E_{i,\min}+X·φ² 를 도입해, 임계값 이하인 노드만을 선택한다. 이 역시 리스트 크기를 동적으로 제한하지만, 여전히 고정된 M에 의존한다.
제안된 알고리즘은 다익스트라의 최단 경로 탐색 원리를 차용하면서, 리스트(우선순위 큐)의 크기를 사전에 정해진 L으로 제한한다. 구체적인 절차는 다음과 같다. (1) 빈 리스트를 초기화하고, 첫 레이어의 모든 후보 노드를 삽입한다. (2) 리스트에서 누적 거리가 최소인 노드 A를 선택하고, A가 리프(깊이 t)라면 해당 경로를 ML 추정값으로 출력한다. (3) A의 자식 노드들을 리스트에 삽입하고, 리스트를 누적 거리 기준으로 정렬한다. (4) 리스트 크기가 L을 초과하면, 누적 거리가 큰 노드들을 삭제한다. (5) 2‑4 과정을 반복한다. 이때 리스트 크기 L은 QRD‑MLD의 M과 동일하게 설정하거나, 성능·복잡도 요구에 따라 조정할 수 있다. 리스트가 제한되므로, 탐색 과정에서 일부 후보가 버려지지만, 실험 결과는 적절한 L 선택 시 SER이 거의 변하지 않으며 평균 연산량이 크게 감소함을 보여준다.
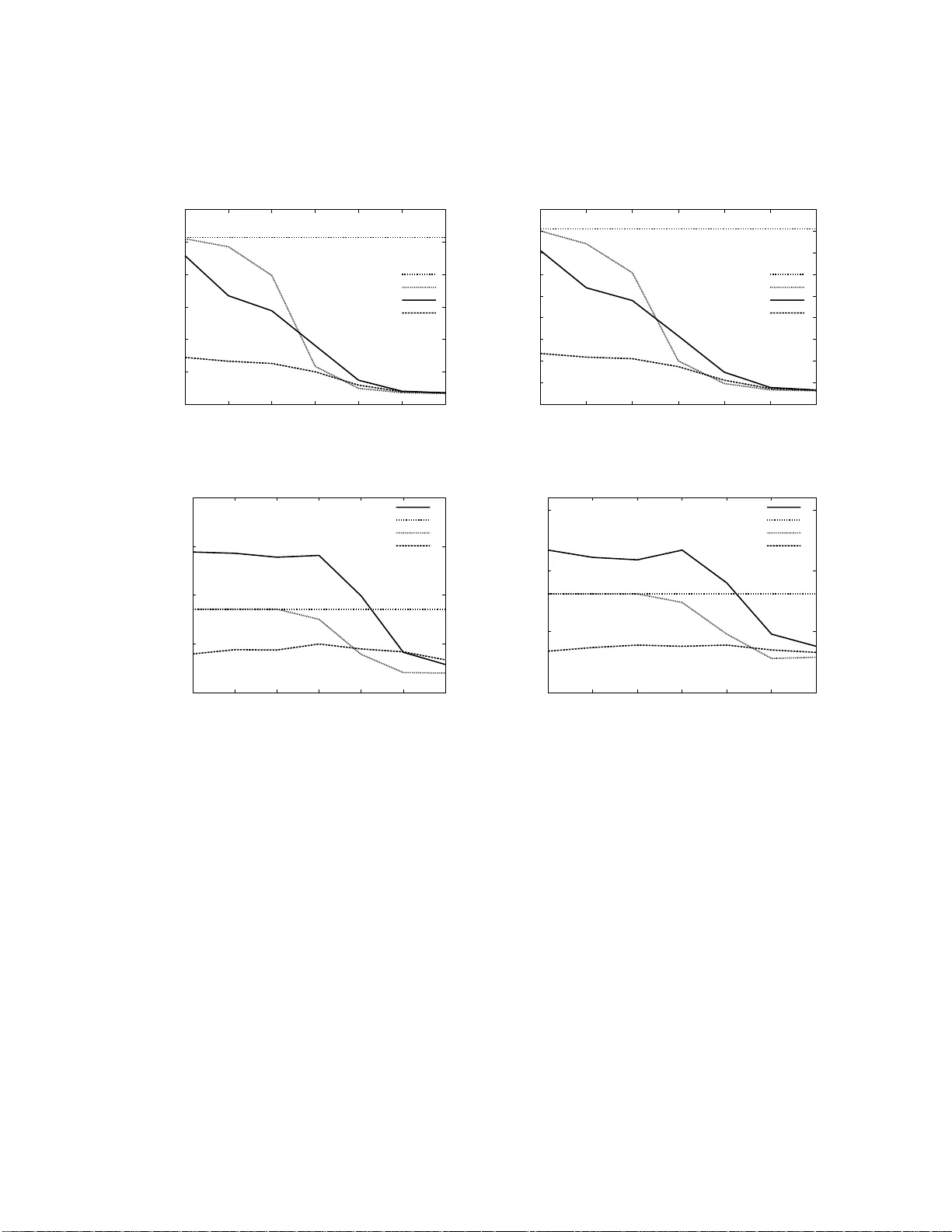
시뮬레이션 설정은 두 가지 시나리오이다. 첫 번째는 4×4 안테나 구성, 두 번째는 6×6 구성이며, 모두 16‑QAM 변조와 AWGN, 복소 정규 분포 페이딩을 사용한다. 채널 행렬은 매 100개의 전송 신호마다 새로 생성한다. 성능 평가는 SER, 평균·최대 연산 복잡도(복소수 곱·나눗셈 횟수), 평균·최대 탐색 노드 수, 실수 비교 연산 횟수 등을 포함한다. 주요 결과는 다음과 같다.
- **SER**: L = 16인 경우, 원본 QRD‑MLD와 거의 동일한 SER을 달성한다. L = 5인 경우에도, QRD‑MLD 개선형과 비교해 저 SNR에서는 약간 높은 SER이지만, 고 SNR에서는 오히려 더 낮은 SER을 보인다.
- **평균 연산 복잡도**: L = 16일 때 평균 복잡도가 원본 QRD‑MLD 대비 약 30 % 감소한다. L = 5일 경우, 저 SNR 구간에서 평균 복잡도가 QRD‑MLD 개선형보다 현저히 낮으며, 고 SNR 구간에서는 비슷한 수준이다.
- **최대 연산 복잡도**: 리스트 크기를 크게 잡을수록 최악 경우 복잡도가 증가하지만, 전체 시뮬레이션 평균에서는 여전히 QRD‑MLD보다 유리하다.
- **탐색 노드 수**: 평균·최대 탐색 노드 수 역시 L = 16일 때 QRD‑MLD보다 적으며, L = 5일 경우 저 SNR에서 특히 크게 감소한다.
- **실수 비교 연산**: 리스트 정렬과 후보 선택 과정에서 발생하는 실수 비교 연산도 L에 비례해 감소한다.
또한, 제안 알고리즘은 LDPC·Turbo와 같은 채널 코딩 후에 N‑most‑likely 후보를 요구하는 상황에서도, 리스트에 N개의 최우선 후보를 남겨두는 방식으로 손쉽게 확장 가능함을 언급한다. 이는 실제 통신 시스템에서 복합적인 디코딩 파이프라인에 자연스럽게 통합될 수 있음을 의미한다.
결론적으로, 리스트 크기 제한 다익스트라 탐색은 QRD‑MLD와 그 개선형이 갖는 고정‑M 기반의 제한을 넘어, 동적 우선순위 관리와 리스트 크기 조정을 통해 평균 복잡도를 크게 낮추면서도 SER을 유지·소폭 개선하는 실용적인 근접 ML 검출 방법으로 평가된다. 향후 연구에서는 리스트 크기 L을 채널 상태·SNR에 따라 자동으로 조정하는 적응형 메커니즘 및 하드웨어 구현 효율성을 탐구할 필요가 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기