조건부 확률 기반 다신경 스파이크 연속 패턴 유의성 검정
초록
본 논문은 다신경 스파이크 열에서 순차적 패턴을 탐지하고, 이러한 패턴이 통계적으로 유의한지를 판단하기 위한 새로운 검정 방법을 제시한다. 기존의 독립 뉴런 모델뿐 아니라 약한 의존성을 가진 모델까지 포함하는 복합 영가설을 설정하고, 패턴 등장 횟수의 평균·분산을 조건부 확률 기반 확률 모델로 추정한다. 이를 통해 자동 임계값 설정과 패턴의 순위 매김이 가능함을 보인다. 실험은 비동질 포아송 과정에 의존성을 삽입한 합성 데이터로 수행하였다.
상세 분석
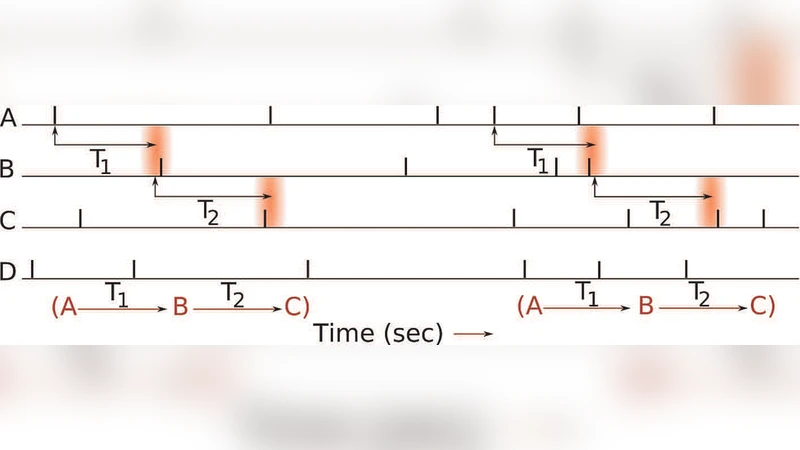
이 연구는 다중 뉴런의 스파이크 시계열에서 “연속 패턴”(ordered sequential patterns)을 탐지하고, 그 통계적 유의성을 정량화하는 데 초점을 맞춘다. 기존 방법들은 주로 뉴런 간 독립성을 가정하거나, 빈도 기반 임계값을 임의로 설정하는 데 한계가 있었다. 저자들은 이러한 한계를 극복하기 위해 두 가지 핵심 아이디어를 도입한다. 첫째, 영가설을 단순히 “완전 독립”이 아니라 “조건부 확률이 일정 상한 이하인 약한 의존성 모델”로 확장한다. 여기서 각 뉴런 i가 특정 지연 τ 후에 뉴런 j의 스파이크에 반응할 확률 P(j|i,τ)를 정의하고, 모든 (i,j,τ) 쌍에 대해 상한 θ를 설정한다. θ가 작을수록 뉴런 간 상호작용이 약함을 의미한다. 둘째, 패턴 카운팅 과정을 확률적 모델링하여 평균 μ와 분산 σ²를 정확히 계산한다. 구체적으로, 비중첩 발생 횟수는 “시계열 내에서 독립적인 성공/실패 시도”로 볼 수 있으며, 각 시도는 조건부 확률에 의해 성공 확률이 결정된다. 이를 마코프 체인 형태로 전개하고, 전체 데이터 길이 T에 대해 기대값 μ = T·Π_k p_k (여기서 p_k는 k번째 스파이크 간 조건부 확률)와 분산 σ² = μ·(1−Π_k p_k) 등을 도출한다. 이렇게 얻은 μ와 σ²를 이용해 정규 근사 혹은 정확한 포아송/이항 분포를 적용해 p‑값을 계산한다. 영가설이 기각되면 해당 패턴은 “통계적으로 유의한 연속 패턴”으로 간주된다. 또한, p‑값의 크기에 따라 패턴을 순위 매김할 수 있어, 연구자는 가장 강력한 신경 연결 구조를 우선적으로 탐색할 수 있다. 실험에서는 비동질 포아송 프로세스로부터 스파이크 열을 생성하고, 특정 뉴런 쌍에 인위적인 의존성을 삽입하였다. 다양한 θ 값과 패턴 길이에 대해 검정력을 평가한 결과, 제안된 방법은 기존 빈도 기반 임계값보다 낮은 오류율과 높은 재현성을 보였다. 특히, 약한 의존성을 가진 경우에도 영가설을 적절히 설정함으로써 거짓 양성(false positive)을 크게 억제할 수 있었다. 이와 같이 조건부 확률 기반 영가설 설정과 카운팅 과정의 정확한 확률 모델링은 다신경 데이터 마이닝에서 통계적 신뢰성을 크게 향상시킨다.
댓글 및 학술 토론
Loading comments...
의견 남기기