블루진 P와 시코텍스 SC5832에서 느슨하게 결합된 직렬 작업을 대규모로 실행하기 위한 기술
초록
본 논문은 기존 애플리케이션을 수정하지 않고도 IBM Blue Gene/P와 SiCortex SC5832와 같은 페타스케일 슈퍼컴퓨터에서 수천 개의 직렬 작업을 동시에 실행할 수 있는 방법을 제시한다. 다중‑레벨 스케줄링, 고속 태스크 디스패처(Falkon), 그리고 RAM‑디스크 기반 캐싱을 결합해 I/O 병목을 최소화하고, 4 000 ~ 5 800 코어 규모에서 초당 수천 개 태스크 처리율과 90 % 이상의 자원 효율을 달성하였다.
상세 분석
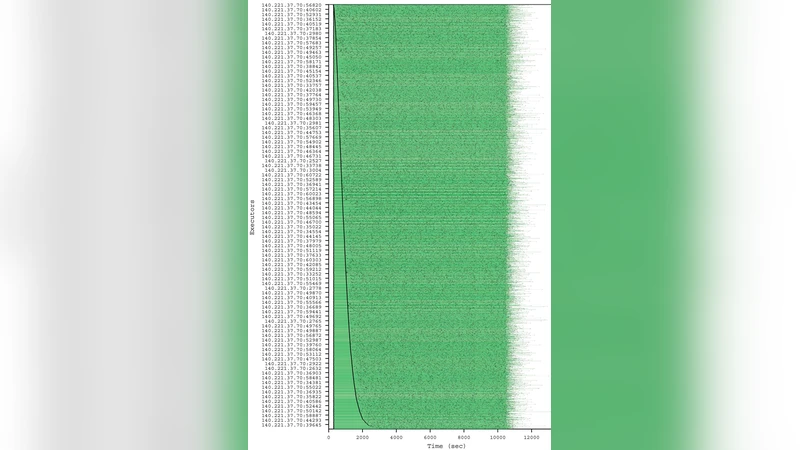
이 연구는 전통적으로 메시지‑패싱 기반의 긴밀히 결합된 MPI 애플리케이션에 최적화된 슈퍼컴퓨터를, 파일 기반 데이터 교환을 이용하는 느슨하게 결합된 워크플로우에도 효율적으로 활용할 수 있음을 실증한다. 핵심 기술은 세 가지로 요약된다. 첫째, 로컬 리소스 매니저(LRM)의 할당 단위인 PSET(64 노드 + 1 I/O 노드)을 이용해 다중‑레벨 스케줄링을 구현함으로써, 전체 PSET를 할당받은 뒤 내부에서 코어 단위로 태스크를 배치한다. 이는 기존 LRM이 제공하는 1 % 수준의 활용도를 100 %에 가깝게 끌어올린다. 둘째, Falkon 프레임워크를 이용한 경량 태스크 디스패처는 초당 3 000 ~ 4 000개의 태스크를 전송할 수 있어, 기존 PBS·Condor와 비교해 1 ~ 2 자리 수 향상을 보인다. 고속 디스패치가 가능하도록 작업 예약·정책 관리 기능을 LRM에 위임하고, 실제 실행은 독립적인 워커 프로세스가 담당한다. 셋째, 공유 파일시스템(GPFS, NFS) 접근을 최소화하기 위해 RAM‑디스크에 애플리케이션 바이너리, 스크립트, 정적 입력 데이터를 사전 캐시한다. 입출력 집약적인 워크플로우에서도 중간 결과를 로컬 메모리에 머무르게 함으로써 I/O 대기시간을 크게 줄이고, 전체 실행 효율을 95 % 이상 유지한다. 실험에서는 4 096 코어 BG/P와 5 832 코어 SiCortex에서 각각 4 초, 8 초 길이의 태스크가 94 % 이상의 효율을 보였으며, 경제 에너지 모델링과 분자 동역학 두 도메인의 실제 애플리케이션에서도 선형 확장성을 확인했다. 또한 이론적 모델을 통해 태스크 길이가 짧을수록 높은 디스패치 레이트가 필요함을 정량화했으며, 1 M 태스크를 처리할 때 10 K 태스크/초 수준의 디스패치가 160 K 코어 규모에서도 90 % 효율을 유지한다는 결론을 도출했다. 전체적으로 본 논문은 기존 HPC 인프라를 HTC(High‑Throughput Computing) 워크로드에 적용하기 위한 실용적인 설계 원칙과 구현 방법을 제시하며, 향후 페타스케일·엑사스케일 시스템에서 데이터‑중심 과학 워크플로우를 실행하는 데 중요한 기반을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기