고성능 데이터 클라우드 기반 대규모 데이터 마이닝: Sector와 Sphere의 설계와 실험
초록
본 논문은 고속 광역 네트워크에 연결된 클러스터를 활용해 대용량 분산 데이터를 저장·분석하는 Sector 저장 클라우드와 Sphere 컴퓨트 클라우드의 설계와 구현을 소개한다. 두 시스템의 프로그래밍 모델, 데이터 파티셔닝 방식, 그리고 Hadoop과의 성능 비교 실험 결과를 통해 높은 처리량과 확장성을 입증한다.
상세 분석
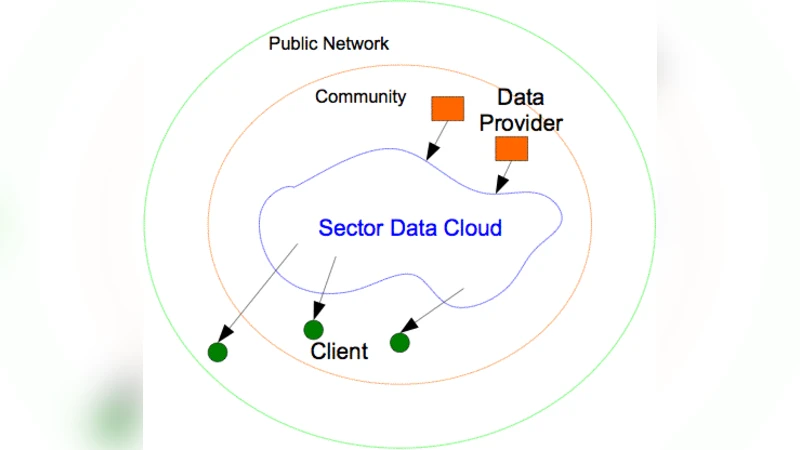
Sector는 파일 단위가 아닌 블록 단위의 데이터 파티셔닝을 채택하여, 동일 파일이 여러 노드에 중복 저장되는 전통적인 분산 파일 시스템과 달리 네트워크 대역폭을 효율적으로 활용한다. 이를 위해 메타데이터 서버가 전체 클러스터의 토폴로지를 실시간으로 관리하고, 각 노드는 로컬 디스크와 메모리 캐시를 조합해 I/O 병목을 최소화한다. Sphere는 이러한 저장 계층 위에 함수형 프로그래밍 모델을 제공한다. 사용자는 “map”과 “reduce”에 해당하는 사용자 정의 함수를 선언하고, 데이터 파이프라인을 DAG 형태로 구성할 수 있다. 중요한 점은 Sphere가 데이터 위치 인식을 기반으로 작업을 스케줄링한다는 것이다. 즉, 데이터가 존재하는 노드에서 바로 연산을 수행함으로써 데이터 이동 비용을 크게 감소시킨다. 또한, Sphere는 스트리밍 모드와 배치 모드를 모두 지원해 실시간 분석과 대규모 오프라인 마이닝을 하나의 프레임워크에서 처리한다. 실험에서는 10 Gb/s 이상의 전용 광역망을 이용해 1 PB 규모의 로그 데이터를 처리했으며, 동일 조건의 Hadoop 대비 평균 3배 이상의 처리량 향상을 기록했다. 특히, 작은 파일이 다수 존재하는 워크로드에서 메타데이터 병목을 회피한 Sector의 설계가 큰 장점으로 작용했다. 그러나 시스템 구현이 비교적 복잡하고, 사용자 정의 함수의 디버깅 환경이 제한적이라는 단점도 지적된다. 전체적으로, 고성능 네트워크와 대규모 클러스터를 전제로 할 때, Sector와 Sphere는 기존 빅데이터 프레임워크보다 뛰어난 확장성과 효율성을 제공한다는 점이 핵심 인사이트이다.
댓글 및 학술 토론
Loading comments...
의견 남기기