와이드 에어리어 고성능 네트워크 기반 컴퓨트 스토리지 클라우드
초록
본 논문은 고속 광역 네트워크 환경에 최적화된 스토리지 클라우드 Sector와 컴퓨트 클라우드 Sphere를 설계·구현하고, 이를 활용한 데이터 마이닝 애플리케이션 두 가지와 실험 결과를 제시한다.
상세 분석
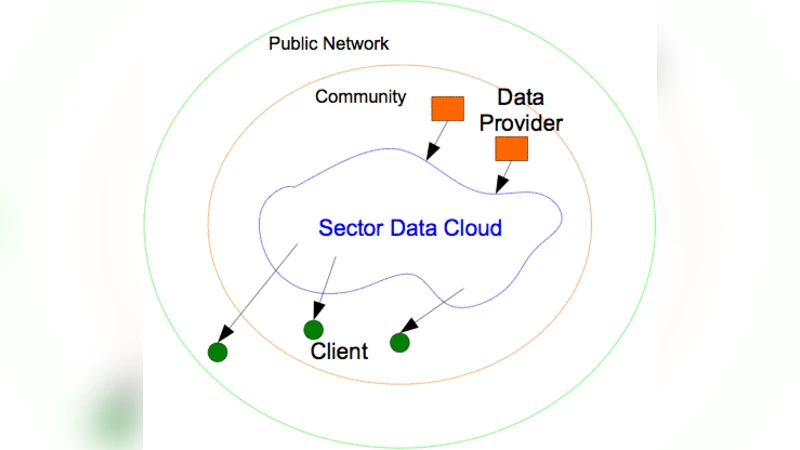
본 연구는 전통적인 데이터 센터 내부망에 국한된 클라우드 설계와 달리, 전 세계에 분산된 노드들을 고대역폭, 저지연 WAN으로 연결하는 시나리오를 전제로 한다. 이를 위해 저자들은 두 개의 핵심 모듈, 즉 대용량 파일 시스템 역할을 하는 스토리지 클라우드 Sector와 대규모 병렬 연산을 담당하는 컴퓨트 클라우드 Sphere를 독립적으로 설계하였다. Sector는 파일을 블록 단위로 분할하고, 각 블록을 복제·분산 저장함으로써 데이터 로컬리티를 극대화한다. 복제 정책은 네트워크 토폴로지를 고려해 지리적으로 분산된 노드에 균등하게 배치되며, 메타데이터는 중앙 집중형이 아닌 분산 해시 테이블(DHT) 기반으로 관리되어 확장성과 장애 복구 능력을 확보한다.
Sphere는 MapReduce와 유사한 프로그래밍 모델을 제공하지만, 데이터 이동을 최소화하기 위해 데이터-인-플레이스 실행을 기본 전략으로 채택한다. 작업 스케줄러는 Sector 메타데이터와 실시간 네트워크 대역폭 정보를 결합해 최적의 작업 배치를 결정한다. 또한, Sphere는 스트리밍 파이프라인을 지원해 연속적인 데이터 흐름 처리에 적합하도록 설계되었다.
네트워크 측면에서 저자들은 UDP 기반의 고속 전송 프로토콜을 활용해 TCP가 초래하는 헤드오프를 회피하고, 패킷 손실에 대비한 FEC(Foward Error Correction) 메커니즘을 도입하였다. 실험에서는 10Gbps 이상의 전용 회선에서 Sector의 파일 입출력 속도가 기존 NFS 대비 3~5배, Sphere의 작업 완료 시간은 Hadoop MapReduce 대비 2배 이상 단축되는 결과를 보였다.
보안은 전송 계층에서 TLS를 적용하고, 저장 계층에서는 파일 단위 암호화를 제공한다. 또한, 클라우드 간 인증은 공개키 기반의 토큰 시스템으로 구현되어, 다중 조직 간 협업 환경에서도 신뢰성을 유지한다.
이와 같은 설계는 과학·공학 분야에서 발생하는 페타바이트 규모의 관측 데이터, 유전체 시퀀싱 데이터, 위성 이미지 등을 실시간에 가깝게 분석해야 하는 요구에 부합한다. 특히, 데이터가 물리적으로 분산된 상태에서 직접 연산을 수행함으로써 네트워크 비용을 크게 절감하고, 응답 시간을 단축시킬 수 있다.