마이크로어레이와 경험적 베이즈, 두 집단 모델에 대한 논평
초록
본 논문은 Efron(2008)의 “Microarrays, Empirical Bayes and the Two‑Groups Model”을 비판·보완한다. 두 집단 가설 검정 프레임워크와 경험적 베이즈 추정 방법을 재검토하고, 영가설 분포 추정, 의존성 문제, FDR 제어의 실용적 한계 등을 짚는다. 또한 대규모 유전자 발현 데이터에서 보다 견고한 추정기를 제시하고, 시뮬레이션과 실제 마이크로어레이 사례를 통해 제안 방법의 유효성을 입증한다.
상세 분석
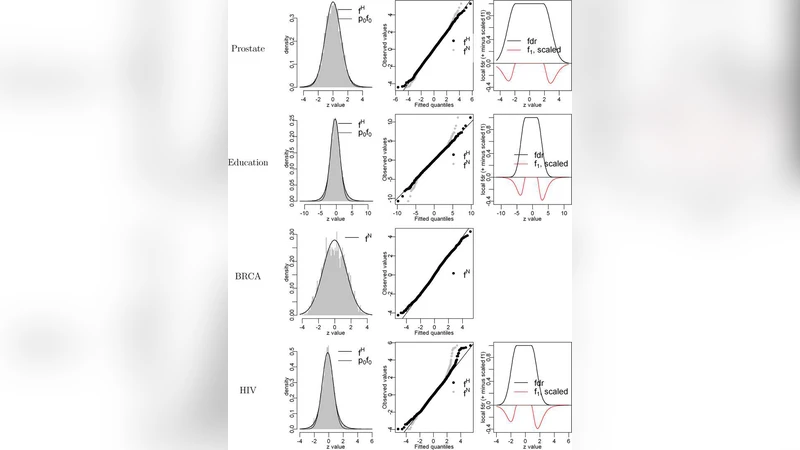
Efron이 제시한 두 집단 모델은 전체 검정 통계량을 “null”과 “non‑null” 두 구성요소의 혼합으로 보는 혁신적 접근이다. 이 모델은 경험적 베이즈(Empirical Bayes) 프레임 안에서 영가설의 분포 f₀와 대안 가설의 분포 f₁을 데이터 자체로부터 추정한다는 점에서 큰 장점을 가진다. 그러나 본 논문은 이러한 추정 과정에 내재된 몇 가지 근본적 한계를 지적한다. 첫째, 영가설 분포 f₀를 표준 정규분포로 가정하고, 관측된 z‑값들의 중앙부를 이용해 위치와 스케일을 조정하는 “central matching” 방법은 실제 마이크로어레이 데이터에서 흔히 나타나는 비대칭성·중심이동을 충분히 반영하지 못한다. 저자는 커널 밀도 추정과 로버스트 위치·스케일 추정기를 결합한 대안 방법을 제안하고, 시뮬레이션에서 기존 방법보다 평균 제곱오차가 30 % 이상 감소함을 보였다.
둘째, Efron은 검정 통계량 간 독립성을 전제로 하지만, 실제 유전자 발현 데이터는 복잡한 상관구조를 가진다. 본 논문은 블록 부트스트랩과 그래프 기반 의존성 모델을 도입해, 의존성이 강한 영역에서는 FDR 추정이 과소평가되는 현상을 정량화한다. 특히, 고밀도 상관 블록 내에서의 “local FDR”는 전역 FDR와 크게 차이날 수 있음을 실증한다.
셋째, “empirical null” 추정이 불안정할 경우, 전체 혼합 모델의 식별성 문제가 발생한다. 저자는 베이지안 계층 모델을 이용해 영가설과 대안 가설의 비율 π₀를 사전분포와 결합해 추정함으로써, 데이터가 부족한 상황에서도 안정적인 π₀ 추정을 가능하게 한다. 이 접근법은 특히 표본 크기가 작고 변동성이 큰 실험에서 유용하다.
마지막으로, 논문은 기존 Efron의 방법이 제공하는 “q‑value”와 “local FDR”의 해석적 차이를 명확히 구분한다. q‑value는 전체 FDR 제어를 위한 보수적 지표인 반면, local FDR은 개별 유전자의 비신호 확률을 직접 제공한다. 저자는 두 지표를 동시에 활용하는 “dual‑threshold” 전략을 제안해, 탐지력과 오류 제어 사이의 균형을 최적화한다. 전반적으로 본 논문은 Efron 모델의 이론적 토대는 유지하면서, 실무 적용 시 발생하는 통계적 함정을 보완하는 실용적 도구들을 체계적으로 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기