마이크로배열과 경험적 베이즈 그리고 두 집단 모델에 대한 논평
본 논평은 Efron의 “Microarrays, Empirical Bayes and the Two‑Group Model”을 비판적으로 검토하며, p‑값 기반 절차의 비효율성을 지적하고 지역 거짓 발견율(Lfdr)의 근본적 역할을 강조한다. 또한 영(0)분포와 비영분포 비율 추정, 그리고 의존성 구조를 고려한 다중 검정 방법의 필요성을 논의한다.
저자: T. Tony Cai
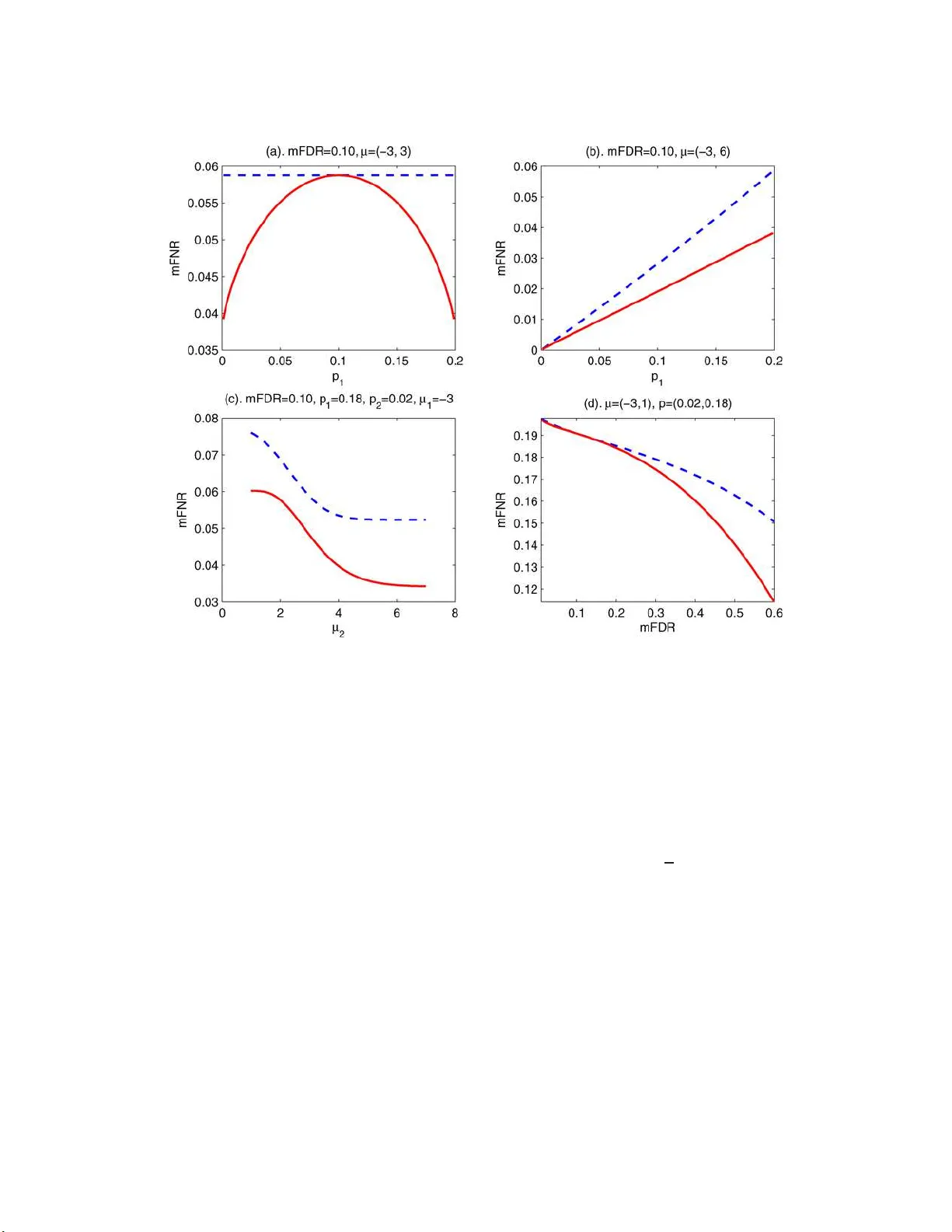
Efron의 원 논문은 마이크로어레이 데이터와 같은 대규모 검정 상황에서 경험적 베이즈와 두 집단 혼합 모델을 도입하여 FDR 제어의 새로운 시각을 제공한다. Cai는 이 논문을 토대로 몇 가지 핵심 이슈를 짚으며, 기존의 p‑값 기반 절차가 효율성 면에서 한계가 있음을 지적한다.
첫 번째로, p‑값은 전통적인 가설 검정에서 핵심적인 역할을 하지만, 대규모 다중 검정에서는 FDR를 제어하면서 동시에 최소의 FNR을 달성하는 효율적인 절차가 요구된다. Sun과 Cai(2007)의 결과에 따르면, p‑값을 순서대로 임계값을 설정하는 방식은 최적이 아니며, 실제 최적 규칙은 Lfdr, 즉 사후 영가설 확률에 기반한다. Lfdr은 우도비와 동일한 순서를 제공하므로, 비대칭적인 비영분포가 존재할 때 특히 큰 이점을 가진다. 예시로 제시된 정규 혼합 모델에서 Lfdr 기반 오라클 절차는 p‑값 기반 오라클 절차보다 모든 설정에서 mFNR이 낮았다. 이는 Lfdr이 비영가설의 분포 정보를 활용하는 반면, p‑값은 오직 영가설만을 기준으로 한다는 근본적인 차이에서 비롯된다.
두 번째로, 실제 데이터에서는 이론적 영분포(N(0,1))가 정확히 맞지 않을 경우가 빈번하다. Efron은 경험적 영분포를 추정해야 한다고 주장했으며, 이를 위해 중앙 히스토그램의 피크와 폭을 이용하는 간단한 방법과, Jin‑Cai(2007)의 고주파 특성함수 기반 추정법을 제시한다. 특히 Jin‑Cai 방법은 고주파 영역에서 비영가설의 영향이 거의 사라지므로 영분포 파라미터를 일관되게 추정할 수 있다. 이러한 영분포와 비영가설 비율(p₀)의 정확한 추정은 Lfdr 계산의 정확성을 좌우하며, 추정 오차가 클 경우 적응형 절차(식 2)의 성능도 저하된다.
세 번째로, 검정 대상 간의 상관관계, 즉 의존성 문제를 다룬다. 유전자 발현 데이터는 종종 클러스터링되거나 경로 단위로 상관관계를 보이는데, 이는 영분포 자체를 왜곡시킬 수 있다. 기존 연구는 주로 FDR 제어의 유효성(예: Benjamini‑Yekutieli, Wu)만을 검증했으며, 효율성 측면에서는 충분히 탐구되지 않았다. Cai는 의존성을 활용하면 검정 파워를 크게 향상시킬 수 있다고 주장한다. 예를 들어, 인접 유전자의 검정 결과를 공동으로 고려하면 지역적인 신호를 더 정확히 포착할 수 있다. 현재는 이러한 의존성을 모델링하는 구체적인 방법이 부족하므로, 향후 연구 과제로 남아 있다.
마지막으로, Cai는 Lfdr 기반 적응형 단계 상승 절차(식 2)를 제안한다. 이 절차는 추정된 Lfdr 값을 누적합하여 α 이하가 되는 최대 인덱스를 찾고, 해당 인덱스 이하의 가설을 모두 기각한다. 이 방법은 mFDR을 asymptotically α 수준에서 제어하면서, mFNR 측면에서도 Lfdr 오라클 절차와 동일한 효율성을 달성한다는 이론적 보장을 제공한다. 실험 결과는 Benjamini‑Hochberg 단계 상승 절차와 기존 p‑값 기반 적응형 절차보다 우수함을 보여준다.
결론적으로, 이 논평은 Lfdr이 대규모 다중 검정의 근본적인 통계량이며, 영분포와 비영가설 비율의 정확한 추정, 그리고 의존성 구조의 적절한 활용이 차세대 통계 방법론의 핵심 과제임을 강조한다. Efron의 작업은 이러한 연구 방향을 제시하는 중요한 출발점이며, 앞으로의 연구는 보다 정교한 추정 기법과 의존성 모델링을 통해 검정 효율성을 극대화하는 데 초점을 맞출 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기