마이크로어레이와 경험적 베이즈 그리고 두 집단 모델
초록
본 논문은 대규모 유전자 발현 데이터와 같은 고처리량 실험에서 수천 개의 가설을 동시에 검정할 때, 전통적인 빈도주의 검정 이론이 직면하는 한계를 짚고, 경험적 베이즈와 두 집단 모델을 결합한 새로운 통계적 프레임워크를 제시한다. 특히 거짓 발견률(FDR) 제어와 영가설 선택, 검정력, 순열 방법의 제한점, 경로 수준 검정, 상관 구조와 다중 신뢰구간 등에 대해 깊이 있게 논의한다.
상세 분석
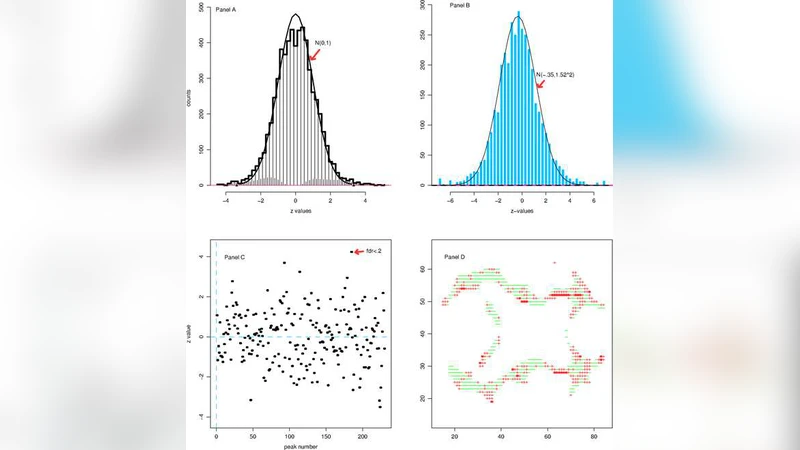
논문은 먼저 고전적 가설 검정 이론이 “하나의 영가설 vs 대안가설”이라는 1대1 구조에 기반해 왔으며, 이는 수십 개 정도의 검정에선 충분했지만, 마이크로어레이와 같은 현대의 대규모 데이터에서는 수천에서 수만 개의 검정이 동시에 수행되는 상황을 전혀 고려하지 못했다는 점을 강조한다. 이러한 상황에서 영가설이 실제 데이터에 얼마나 잘 맞는가를 판단하기 위해 경험적 베이즈 접근법이 도입된다. 경험적 베이즈는 전체 검정 집합을 하나의 혼합 모델, 즉 두 집단 모델(zero‑inflated mixture)로 보며, 각 검정 통계량이 ‘null’ 혹은 ‘non‑null’ 두 그룹 중 하나에서 생성된다고 가정한다. 이때 영가설 비율 π0와 비영가설 분포 f1(z)를 데이터로부터 추정한다는 점이 핵심이다.
두 집단 모델은 베이즈적 사후 확률인 ‘local false discovery rate (lfdr)’을 정의하게 해 주며, 이는 각 검정에 대한 영가설이 참일 확률을 직접 제공한다. lfdr은 전통적인 p‑값 기반 FDR와는 달리 검정 통계량 자체의 분포 정보를 활용하므로, 비대칭적이거나 꼬리 부분이 두꺼운 경우에도 보다 정확한 오류 제어가 가능하다. 논문은 특히 Benjamini‑Hochberg(FDR) 절차와의 연결 고리를 명확히 제시한다. BH 절차는 전체 FDR을 제어하지만, 개별 검정에 대한 사후 확률을 제공하지 않는다. 반면 두 집단 모델은 사후 확률을 통해 검정 순서를 재조정하고, 필요시 ‘adaptive’ BH 절차와 결합해 더 높은 검정력을 얻을 수 있음을 보인다.
또한 영가설의 선택 문제를 심도 있게 다룬다. 전통적으로는 ‘point null’(μ=0)를 가정하지만, 실제 생물학적 현상에서는 미세한 효과도 무시할 수 없으며, ‘interval null’ 혹은 ‘practical null’ 개념이 필요하다. 경험적 베이즈는 데이터에 기반해 영가설 분포를 추정함으로써, 이러한 실질적 영가설을 자동으로 반영한다.
순열 검정은 종종 독립성 가정을 위배하거나, 계산 비용이 prohibitive한 경우가 많다. 논문은 순열 방법이 전체 검정 통계량의 결합 분포를 추정하는 데는 유용하지만, 개별 검정에 대한 정확한 lfdr을 제공하지 못한다는 한계를 지적한다. 대신, 경험적 베이즈는 전체 데이터에서 영가설 비율과 비영가설 분포를 동시에 추정함으로써, 순열보다 효율적이고 확장 가능한 대안을 제시한다.
다음으로 경로 수준 검정, 즉 유전자 집합이나 생물학적 네트워크와 같은 그룹 단위의 가설 검정에 대해 논한다. 두 집단 모델을 확장해 그룹 전체에 대한 ‘group‑wise lfdr’를 정의하고, 이를 통해 특정 경로가 전반적으로 변형되었는지를 평가한다. 상관 구조가 존재할 경우, 독립성 가정이 깨져 FDR 제어가 부정확해질 수 있다. 논문은 상관을 고려한 ‘empirical null’ 추정과, 부트스트랩 기반의 상관 보정 방법을 제시한다.
마지막으로 다중 신뢰구간을 구성하는 방법을 논의한다. 베이즈적 접근은 사후 분포를 직접 이용해 각 파라미터에 대한 ‘credible interval’를 제공하고, 동시에 전체 오류율을 제어하는 ‘simultaneous credible region’를 설계할 수 있다. 이는 전통적인 빈도주의 신뢰구간보다 직관적이며, 다중 비교 상황에서도 일관된 해석을 가능하게 한다. 전체적으로 논문은 베이즈와 빈도주의가 상호 보완적으로 작용할 수 있는 통합 프레임워크를 제시하며, 특히 대규모 유전체 데이터 분석에 있어 실용적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기