프리밸리데이션의 통계적 한계와 퍼뮤테이션 검정 제안
고차원 데이터에서 만든 예측 규칙을 기존 임상 지표와 같은 데이터셋에서 비교할 때, 기존의 “재사용” 방식은 과적합으로 편향을 일으킨다. 논문은 이를 보완하기 위한 프리밸리데이션(PV) 절차를 분석하고, PV 후에 적용되는 1자유도 t‑검정이 실제 수준보다 과대·과소 평가될 수 있음을 보인다. 이를 해결하기 위해 제안된 퍼뮤테이션 검정은 명목 수준을 유지하면서 기존 검정과 비슷한 검정력을 제공한다.
저자: ** Holger Höfling (Stanford University) Robert Tibshirani (Stanford University) **
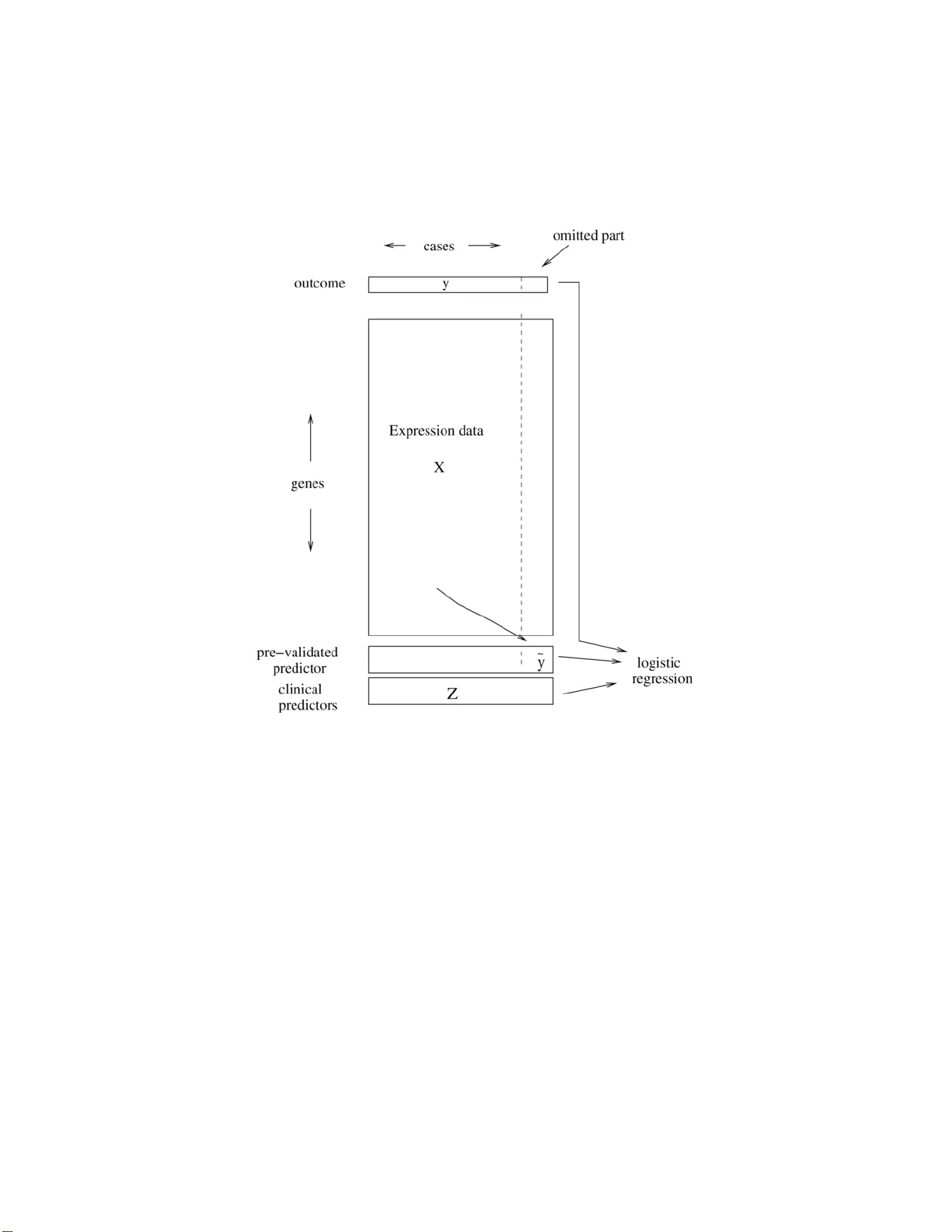
본 논문은 고차원 데이터, 특히 마이크로어레이와 같은 유전체 데이터에서 도출된 새로운 예측 규칙을 기존 임상 변수와 동일 데이터셋 내에서 비교할 때 발생하는 통계적 편향을 체계적으로 분석하고, 이를 보정하기 위한 새로운 검정 방법을 제안한다.
1. **배경 및 문제 정의**
- 고차원 데이터에서 예측 모델을 구축하고 이를 기존 임상 변수와 비교하려면, 동일 데이터를 두 번 사용하게 되는 “재사용” 방법이 일반적이다. 이는 새로운 모델이 훈련에 사용된 데이터를 그대로 테스트에 활용함으로써 과적합(over‑fitting) 편향을 야기한다.
- 데이터가 제한적인 경우, 전통적인 훈련/테스트 분할이나 K‑fold 교차검증을 이용해 모델을 평가하면 훈련 데이터가 감소해 예측 정확도가 떨어지거나, 테스트 샘플이 너무 작아 통계적 검정력이 저하되는 문제가 있다.
2. **프리밸리데이션(PV) 절차**
- PV는 교차검증과 유사하게 데이터를 K개의 폴드로 나눈다. 각 폴드에 대해 나머지 K‑1 폴드로 내부 예측 모델을 학습하고, 제외된 폴드에 대한 예측값을 얻는다. 이렇게 하면 모든 샘플에 대해 “프리밸리데이션된” 예측값 ỹ가 생성된다.
- ỹ는 실제 새로운 데이터에 적용된 예측값과 동일한 통계적 성질을 갖도록 설계되었으며, 따라서 외부 로지스틱 회귀(또는 선형 회귀) 모델에 ỹ와 기존 변수들을 동시에 넣어 β_PV의 유의성을 검정한다.
3. **분석 검정의 편향**
- 기존 연구에서는 1 자유도 t‑검정(또는 z‑검정)을 사용해 β_PV=0 vs. β_PV>0를 검정한다. 그러나 저자는 내부 모델이 선형이고 외부 모델도 선형인 가장 단순한 경우를 수학적으로 분석하여, 분석 검정이 실제 유의수준을 초과하거나 미달할 수 있음을 증명한다.
- 핵심 원인은 ỹ가 훈련 데이터와 완전히 독립되지 않으며, 외부 회귀 모델에 다시 투입될 때 잔차 구조가 변형돼 표준 오류 추정이 부정확해진다. 결과적으로 검정통계량이 기대값이 0이 아닌 편향을 띠게 된다.
4. **퍼뮤테이션 검정 제안**
- 편향을 보정하기 위해, 반응 변수(또는 ỹ)를 무작위로 섞어 PV 과정을 여러 번 반복한다. 각 반복에서 얻은 β̂_PV 값을 귀무분포의 표본으로 사용해 p‑값을 계산한다.
- 이 방법은 데이터 의존성을 그대로 유지하면서 정확한 귀무분포를 추정하므로, 명목 수준을 정확히 유지한다.
5. **시뮬레이션 연구**
- 다양한 시나리오(신호‑대‑잡음 비율, 변수 수, K값, 내부·외부 모델 형태)를 설정해 1,000회 이상 시뮬레이션을 수행하였다.
- 결과: 퍼뮤테이션 검정은 α=0.05에서 실제 거짓 양성 비율이 0.05에 근접했으며, 검정력도 분석 검정과 거의 동일했다. 반면, 분석 검정은 경우에 따라 과대 혹은 과소 평가되는 경향을 보였다.
6. **실제 데이터 적용**
- 78명의 유방암 환자와 4,918개의 유전자 발현 데이터를 사용하였다. 두 가지 예측 모델을 적용했는데, 첫 번째는 van’t Veer 등(2002)의 70개 유전자 서명, 두 번째는 L1 페널티를 적용한 로지스틱 회귀 모델이다.
- 10‑fold PV를 100번 반복한 뒤, 분석 검정은 마이크로어레이 기반 예측변수가 통계적으로 유의하다고 판단했지만, 퍼뮤테이션 검정은 모두 비유의적(p>0.05)이었다. 이는 앞서 이론적으로 제시한 분석 검정의 편향이 실제 데이터에서도 실재함을 보여준다.
7. **결론 및 향후 과제**
- 프리밸리데이션은 새로운 고차원 예측 규칙을 기존 변수와 비교할 때 편향을 크게 감소시키는 효과적인 절차이다. 그러나 그 후에 적용되는 전통적인 1 자유도 검정은 여전히 신뢰할 수 없으며, 퍼뮤테이션 기반 검정이 이를 보완한다.
- 향후 연구에서는 퍼뮤테이션 검정을 Cox 비례위험 모델, 서바이벌 분석 등 다양한 외부 모델에 적용하고, 실제 임상 의사결정 과정에서의 영향력을 정량화하는 것이 필요하다. 또한, 계산 효율성을 높이기 위한 빠른 퍼뮤테이션 알고리즘 개발도 중요한 과제로 남는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기