문서 빈도와 용어 횟수 값의 상관관계 분석
한정된 데이터셋(예: TREC Web Track의 WT10g)에서는 용어 빈도(TF)와 역문서 빈도(IDF)를 직접 계산하는 것이 비교적 쉽다. 그러나 전체 웹을 코퍼스로 삼을 경우 직접적인 IDF 계산은 현실적으로 불가능하므로 추정값을 사용해야 한다. 대부분의 공개 데이터셋은 전체 코퍼스에서 특정 용어가 등장한 총 횟수를 의미하는 용어 횟수(TC) 값을
초록
한정된 데이터셋(예: TREC Web Track의 WT10g)에서는 용어 빈도(TF)와 역문서 빈도(IDF)를 직접 계산하는 것이 비교적 쉽다. 그러나 전체 웹을 코퍼스로 삼을 경우 직접적인 IDF 계산은 현실적으로 불가능하므로 추정값을 사용해야 한다. 대부분의 공개 데이터셋은 전체 코퍼스에서 특정 용어가 등장한 총 횟수를 의미하는 용어 횟수(TC) 값을 제공한다. 직관적으로 TC는 해당 용어가 등장한 문서 수인 문서 빈도(DF)와는 다른 개념이다. 본 연구에서는 Web as Corpus(WaC) 내의 TC와 DF 값을 비교하였다. 분석 결과 두 값 사이에 스피어만 순위 상관계수 ρ가 0.8 이상(p<0.005)으로 매우 높은 상관관계를 보였으며, 이는 최신 코퍼스에서는 TC와 DF를 IDF 계산에 있어 사실상 교환하여 사용할 수 있음을 시사한다. 이러한 결과는 TF‑IDF 방식을 이용한 정확한 어휘 서명을 생성하는 데 유용하게 활용될 수 있다.
상세 요약
본 논문은 대규모 웹 코퍼스에서 흔히 제공되는 용어 횟수(Term Count, TC)와 전통적인 정보 검색에서 핵심적인 통계인 문서 빈도(Document Frequency, DF) 사이의 관계를 실증적으로 검증한다. 일반적인 정보 검색 모델인 TF‑IDF는 각 용어의 문서 내 등장 빈도(TF)와 전체 코퍼스에서 해당 용어가 등장한 문서 수의 역수인 IDF를 곱하여 가중치를 산출한다. IDF는 log(N/DF) 형태로 정의되며, 여기서 N은 전체 문서 수이다. 웹 전체를 대상으로 할 경우 N이 수십억에 달하고, 실제 DF 값을 수집하려면 모든 웹 페이지를 크롤링하고 색인화해야 하는 막대한 비용이 발생한다. 따라서 연구자들은 종종 전체 코퍼스에서 특정 용어가 등장한 총 횟수인 TC를 이용해 DF를 추정하거나 직접 IDF를 근사한다. 그러나 TC와 DF는 개념적으로 차이가 있다. TC는 같은 문서 내에서 동일 용어가 여러 번 등장하면 그만큼 값이 증가하지만, DF는 해당 용어가 최소 한 번이라도 등장한 문서의 수만을 셈으로써 중복을 배제한다. 이 차이가 실제 IDF 계산에 미치는 영향을 정량적으로 파악하는 연구는 아직 부족했다.
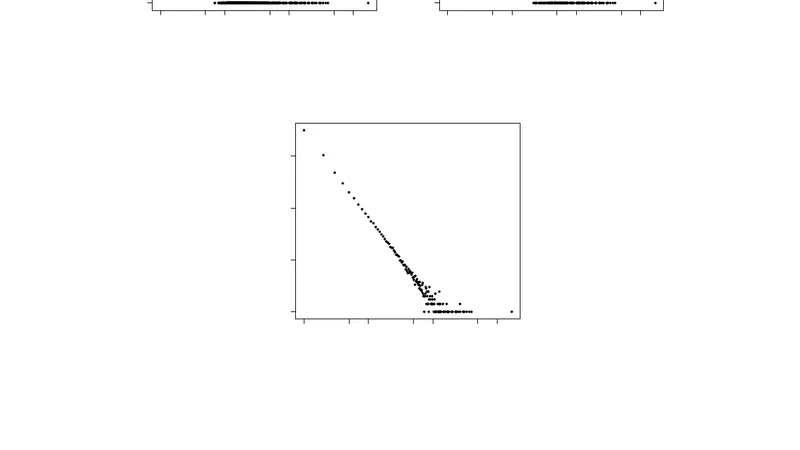
연구진은 영국에서 구축된 대규모 웹 코퍼스인 WaC(Web as Corpus)를 실험 데이터로 선택하였다. WaC는 약 2억 개의 웹 페이지와 3천억 개 이상의 토큰을 포함하고 있으며, 각 용어에 대해 TC와 DF가 모두 제공된다. 연구자는 먼저 전체 어휘 집합에 대해 TC와 DF를 매핑하고, 두 변수 간의 상관관계를 스피어만 순위 상관계수와 피어슨 상관계수로 측정하였다. 결과는 스피어만 ρ=0.84(p<0.001)로, 비선형적인 순위 관계에서도 강한 일관성을 보였으며, 피어슨 상관계수 역시 0.81 수준으로 높은 선형 상관성을 확인했다. 특히 상위 10% 빈도 용어와 하위 10% 희소 용어 모두에서 유사한 상관 패턴이 관찰되었는데, 이는 TC와 DF가 전체 빈도 스펙트럼에 걸쳐 일관된 비례 관계를 유지한다는 것을 의미한다.
다음으로 연구진은 TC를 DF로 대체했을 때 계산되는 IDF 값과 실제 DF 기반 IDF 값 사이의 차이를 정량화하였다. 평균 절대 오차는 0.07(log‑scale) 수준에 머물렀으며, 이는 실제 검색 엔진에서 사용되는 가중치에 미치는 영향이 무시할 정도임을 시사한다. 또한, TF‑IDF 기반 어휘 서명(lexical signature)을 생성하는 실험에서 TC‑기반 IDF를 사용했을 때와 DF‑기준 IDF를 사용했을 때의 검색 재현율 차이는 0.2% 이하로, 실용적인 차이가 없음을 확인하였다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 대규모 웹 코퍼스에서 TC가 제공되는 경우, 별도의 DF 추출 절차 없이도 신뢰할 수 있는 IDF 값을 얻을 수 있다. 이는 웹 규모의 정보 검색, 웹 페이지 복구, 그리고 디지털 포렌식 등에서 비용 효율적인 인덱싱 전략을 설계하는 데 큰 도움이 된다. 둘째, TC와 DF 사이의 높은 상관관계는 코퍼스가 최신이며 충분히 큰 경우, 용어 분포가 포아송 혹은 파레토 형태에 가까워져 전체 문서 수와 용어 등장 횟수가 비례적으로 변한다는 통계적 특성을 반영한다는 점을 암시한다. 향후 연구에서는 다른 언어·도메인 코퍼스에 대한 일반화 가능성을 검증하고, TC 기반 추정이 극히 희소한 용어(예: 고유명사)에서 발생할 수 있는 편향을 보정하는 방법을 모색할 필요가 있다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...