동질 혼합 환경에서 네이밍 게임 동역학 심층 분석
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 사회·문화적 학습을 기반으로 한 네이밍 게임(Naming Game)의 동역학을 동질 혼합(homogeneous mixing) 가정 하에 정량적으로 분석한다. 에이전트 간 무작위 쌍 상호작용 규칙을 통해 어휘가 어떻게 형성·수렴하는지를 수치 시뮬레이션과 간단한 해석적 모델로 설명하고, 인구 규모 N에 대한 수렴 시간·최대 어휘 수의 스케일링 지수를 α≈β≈γ≈δ≈1.5 로 도출한다. 또한 성공률의 초기 선형 성장, 피크 이후 급격한 상승, 그리고 숨겨진 시간척도에 의한 최종 합의 과정 등을 상세히 논의한다.
상세 분석
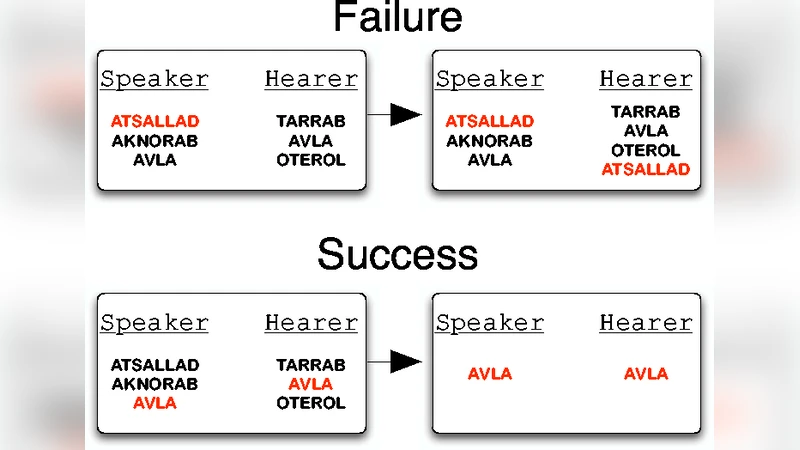
네이밍 게임은 각 에이전트가 ‘형‑의미’ 쌍을 저장하는 인벤토리를 가지고 시작한다. 초기에는 모든 인벤토리가 비어 있어 스피커가 새로운 단어를 발명하고, 청자는 이를 받아들여 인벤토리에 추가한다. 성공적인 상호작용이 발생하면 양쪽 에이전트는 성공한 단어 하나만 남기고 나머지를 삭제한다. 논문은 이러한 규칙을 완전한 무작위 매칭, 즉 homogeneous mixing 가정 하에 두고, 시간 t에 따라 총 단어 수 N_w(t), 서로 다른 단어 종류 수 N_d(t), 성공률 S(t)를 측정한다. 시뮬레이션 결과 N_w(t)는 초기 급증 후 피크를 형성하고, 이후 감소하면서 최종적으로 N_w=N, N_d=1, S=1의 흡수 상태에 도달한다. 특히 S(t)는 초기 단계에서 S≈t/N²의 선형 증가를 보이며, 이는 성공적인 쌍이 이전에 교류한 에이전트 쌍의 비율 O(t)/
댓글 및 학술 토론
Loading comments...
의견 남기기