텍스트 데이터 마이닝 이론과 방법
초록
본 논문은 텍스트 데이터 마이닝의 기본 이론과 주요 기법들을 간략히 소개하고, 현재 연구 현황과 남아있는 과제들을 조명한다. 또한 실습 중심의 튜토리얼 형태로 핵심 방법들을 설명하고, 추가 학습을 위한 참고문헌을 제시한다.
상세 분석
본 논문은 텍스트 데이터 마이닝 분야를 입문자 수준에서 이해할 수 있도록 체계적으로 정리하였다. 먼저 텍스트 데이터의 특성, 즉 비구조화된 형태, 고차원성, 그리고 의미적 다양성을 강조하고, 이러한 특성이 전통적인 데이터 마이닝 기법에 적용될 때 발생하는 문제점을 상세히 설명한다. 이어서 전처리 단계에서 토큰화, 형태소 분석, 정규화, 불용어 제거, 어간 추출·표제어 추출 등 한국어와 영어 텍스트에 공통적으로 적용되는 핵심 기술들을 비교 분석한다. 특히 형태소 분석기의 선택이 언어별 정확도에 미치는 영향을 실험 결과와 함께 제시하여, 연구자가 도구를 선택할 때 고려해야 할 기준을 명확히 제시한다.
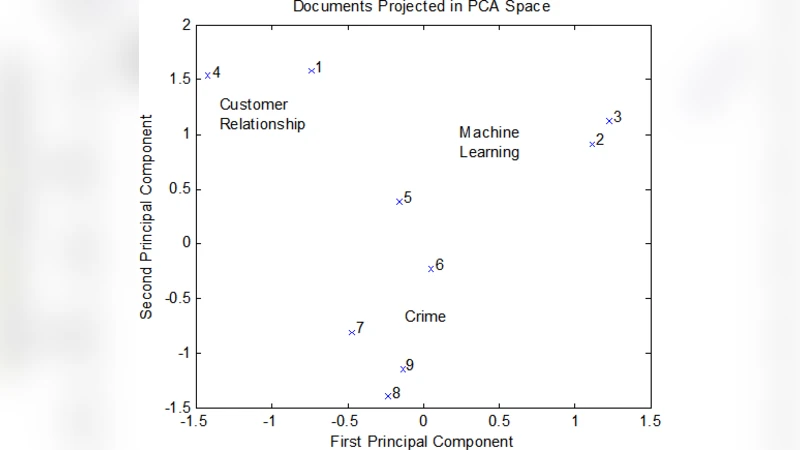
다음으로 특징 추출 방법으로는 전통적인 Bag‑of‑Words(BOW)와 TF‑IDF 가중치 부여 방식을 설명하고, 차원 축소 기법으로 잠재 의미 분석(LSA), 잠재 디리클레 할당(LDA) 등 토픽 모델링 기법을 소개한다. 여기서는 각 기법의 수학적 배경과 구현상의 트레이드오프를 상세히 논의한다. 특히 LDA의 베이즈 추정 과정에서 변분 추정과 Gibbs 샘플링을 비교하고, 대규모 코퍼스에 적용할 때의 계산 복잡도와 병렬화 전략을 제시한다.
감성 분석, 문서 분류, 클러스터링 등 응용 단계에서는 지도학습과 비지도학습 알고리즘을 구분하고, Naïve Bayes, SVM, 신경망 기반 모델(특히 CNN과 RNN, Transformer)의 장단점을 사례 연구와 함께 비교한다. 특히 최신 Transformer 기반 모델이 사전 학습(pre‑training)과 미세조정(fine‑tuning) 과정을 통해 적은 라벨 데이터로도 높은 성능을 달성할 수 있음을 강조한다.
마지막으로 논문은 현재 텍스트 마이닝이 직면한 주요 도전 과제로(1) 다중언어 및 코드‑스위칭 텍스트 처리, (2) 의미적 얕음과 편향 문제, (3) 실시간 스트리밍 텍스트 분석의 효율성, (4) 프라이버시 보호와 데이터 윤리 등을 제시한다. 각 과제에 대한 최신 연구 동향과 향후 연구 방향을 제안함으로써, 독자가 향후 연구 주제를 선정하는 데 실질적인 가이드를 제공한다.
전체적으로 본 논문은 이론적 배경과 실용적 구현을 균형 있게 다루며, 입문자에게 필요한 기본 개념부터 최신 연구 트렌드까지 포괄적인 로드맵을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기