두 히스토그램 일관성 검정
초록
본 논문은 두 개의 히스토그램이 동일한 확률분포에서 추출되었는지를 검정하기 위한 여러 통계적 방법을 비교한다. 연속분포에 대한 1표본 검정들을 2표본 그룹화 데이터에 적용하고, 완전히 규정되지 않은 영가설 하에서 “toy” Monte‑Carlo 시뮬레이션을 이용한 p‑값 추정의 함정을 논의한다. χ², Kolmogorov‑Smirnov, Bhattacharyya 거리, Cramér‑von‑Mises, Anderson‑Darling 등 다양한 검정법을 실험에 적용해 보았으며, 어느 하나가 모든 상황에서 최적이라고는 할 수 없음을 확인한다.
상세 분석
논문은 먼저 두 히스토그램을 동일한 bin 구성을 갖는 다변량 포아송 과정으로 모델링한다. 각 히스토그램의 bin 평균을 μ와 ν으로 두고, 전체 카운트 N_u, N_v를 정의한다. 영가설 H₀는 (1) bin‑by‑bin 평균이 동일한 경우와 (2) 전체 형태(shape)만 동일하고 전체 정규화는 다를 수 있는 경우로 나뉜다. 대규모 데이터에서는 각 bin을 정규분포로 근사해 Δ_i = u_i – v_i의 분산 σ_i² ≈ u_i+v_i 로 두고, χ² 통계량 T = Σ (Δ_i)²/(u_i+v_i) 를 계산한다. 이때 σ_i²를 실제 관측값으로 대체함으로써 근사 χ² 자유도 k(또는 k‑1) 를 사용한다. 저자는 이 근사가 작은 카운트가 존재할 경우 보수적으로 동작한다는 점을 강조한다.
다음으로, 정규화가 다른 경우를 다루기 위해 두 히스토그램을 동일한 총 카운트 N = (N_u+N_v)/2 로 스케일링하고, 스케일된 값에 대해 동일한 χ² 통계량을 적용한다. 이 과정은 형태 비교에 초점을 맞추며, 자유도는 k‑1이 된다.
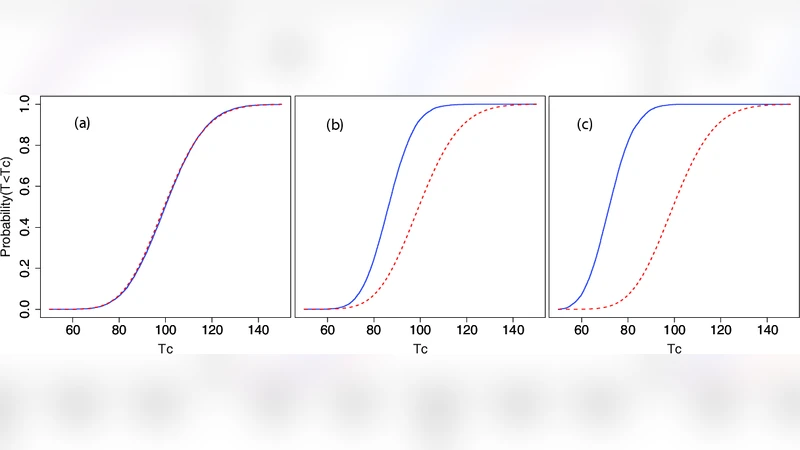
실제 예시(Fig.1)에서는 총 카운트가 492와 424로 차이가 나며, 두 히스토그램은 10% 수준의 평균 차이를 가지고 생성되었다. 표 I에 제시된 결과에 따르면, 절대 비교와 형태 비교 모두 χ² 기반 p‑값이 0.86~0.96 사이로 높은 일관성을 보였지만, “toy” Monte‑Carlo 시뮬레이션을 통해 얻은 경험적 p‑값도 거의 일치한다. 이는 χ² 근사가 어느 정도 타당함을 시사한다.
하지만 저자는 영가설이 완전히 명시되지 않은 상황에서 발생하는 문제를 강조한다. 포아송 평균 μ와 ν을 알 수 없기 때문에 최대우도 추정값을 사용하지만, 이는 작은 카운트 영역에서 과보수(conservative) 혹은 과민(anti‑conservative)하게 작동할 수 있다. 이를 보완하기 위해 저자는 “큰 T 값에 대해 χ² 분포가 실제 분포보다 더 큰 꼬리를 가진다”는 정리를 제시하고, 이를 통해 χ² 기반 p‑값이 실제보다 보수적일 가능성을 논증한다.
다양한 검정법을 추가로 비교한다. Kolmogorov‑Smirnov, Cramér‑von‑Mises, Anderson‑Darling 등 비모수 검정은 연속형 데이터에 적합하지만, 히스토그램과 같이 이산형 빈 카운트에 직접 적용하면 자유도가 불명확해진다. Bhattacharyya 거리(BDM)는 두 히스토그램을 정규화된 벡터로 보고 내적을 이용해 형태 유사성을 측정한다. 표 I에 따르면 BDM은 0.986의 값으로 매우 높은 유사성을 나타냈으며, 이에 대응하는 p‑값은 0.97로 거의 무시할 수 없는 차이를 보이지 않는다.
저자는 또한 “bin 결합” 전략을 제안한다. 각 bin에 최소한의 카운트(minBin)를 확보하도록 인접 bin을 합치는 방식이다. 이 방법은 작은 카운트로 인한 정규근사의 부정확성을 완화시키지만, 통계적 파워를 감소시킬 위험이 있다. Fig.3은 minBin을 변화시켰을 때 T 값과 p‑값이 어떻게 변하는지를 보여준다.
마지막으로 전체 정규화(총 카운트)만을 검정하는 방법을 제시한다. 두 히스토그램의 총 카운트를 이항분포로 모델링하고, μ_T = ν_T 를 검정하는 uniformly most powerful test를 적용한다. 예시에서는 총 카운트 차이에 대한 양측 검정 p‑값이 0.027로, 앞서 형태 검정에서 얻은 0.025와 일치한다. 이는 정규화 차이가 전체 일관성 판단에 중요한 역할을 할 수 있음을 시사한다.
전반적으로 논문은 “하나의 검정이 모든 상황을 지배한다”는 생각을 부정하고, 데이터의 통계량(카운트 규모, bin 수, 정규화 여부)에 따라 적절한 검정법을 선택해야 함을 강조한다. 특히 영가설이 완전히 규정되지 않은 경우, Monte‑Carlo 기반의 경험적 p‑값 추정과 χ² 근사의 보수성 사이의 균형을 신중히 고려해야 한다는 점이 핵심이다.
댓글 및 학술 토론
Loading comments...
의견 남기기