투과성 분석을 위한 정보 입자화 이론 적용
** 본 논문은 인공신경망 기반 셀프오가니징맵(SOM)과 신경‑퍼지 추론시스템(NFIS)을 결합한 정보 입자화(Granulation) 기법을 제시하고, 이를 이란 Shivashan 댐의 루게온(투과성) 데이터에 적용한다. 초기의 거친(크리스프) 입자를 SOM으로 생성하고, 이를 기반으로 퍼지 입자를 NFIS로 재구성한다. 입자 간 균형을 맞추기 위해 ‘규칙의 단순성’과 ‘오차 임계값’ 두 기준을 사용한 폐‑열(open‑close) 반복 과정…
저자: M.Sharifzadeh, H.Owladeghaffari, K.Shahriar
**
본 논문은 지반공학에서 중요한 과제인 암반 투과성(루게온) 변동을 정량적으로 분석하기 위해 정보 입자화(Information Granulation, IG) 이론을 적용한 새로운 방법론을 제시한다. IG 이론은 데이터의 유사성, 기능적 인접성, 혹은 구별 불가능성에 기반해 데이터를 ‘입자’(granule)라는 단위로 묶는 개념이며, 크리스프 입자와 퍼지 입자로 구분된다. 저자는 이론적 배경을 바탕으로 세 단계의 계층적 입자화 과정을 설계하였다.
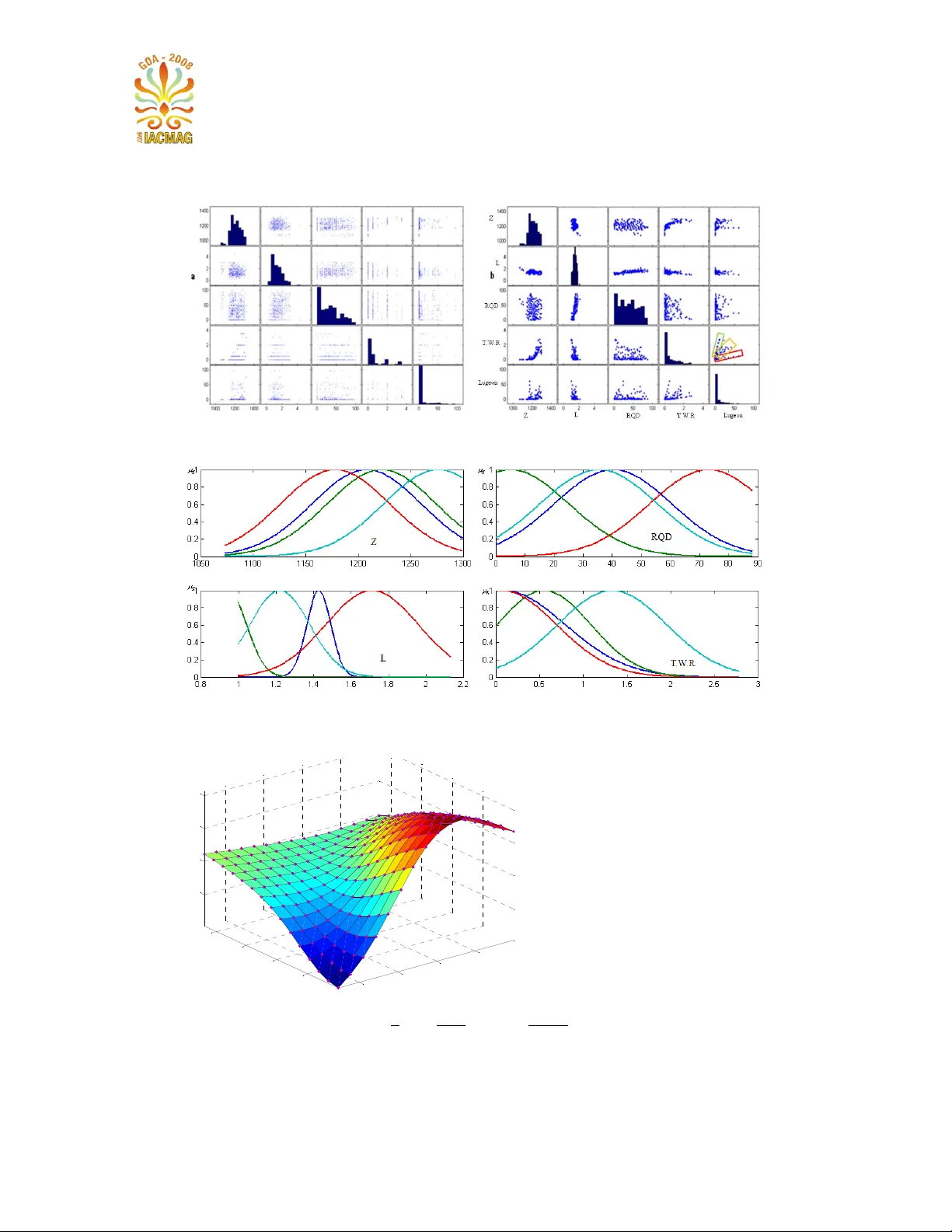
첫 번째 단계는 ‘크리스프 입자’ 생성이다. 여기서는 셀프오가니징맵(Self‑Organizing Map, SOM)을 이용해 원시 루게온 데이터를 저차원 격자 형태의 군집으로 압축한다. SOM은 경쟁 학습을 통해 입력 벡터와 가장 가까운 뉴런을 승자로 선정하고, 승자와 인접한 뉴런들의 가중치를 입력에 가까워지도록 조정한다. 이 과정은 데이터의 고유 구조를 보존하면서 차원을 축소한다. 논문에서는 10 × 15(=150) 뉴런 격자를 500번 학습시켜 150개의 크리스프 입자를 얻었다. 입자 수준은 ‘입자 수(뉴런 수)’와 ‘학습 반복 횟수’라는 두 파라미터로 제어된다.
두 번째 단계는 ‘퍼지 입자’ 생성이다. 크리스프 입자를 NFIS(Neuro‑Fuzzy Inference System)의 입력으로 사용한다. NFIS는 Takagi‑Sugeno‑Kang(TSK) 모델을 채택하여 각 입력 변수에 가우시안 멤버십 함수를 두 개씩 할당하고, 선형 결합 형태의 규칙을 학습한다. 규칙 수와 오차 수준을 동시에 고려하는 ‘폐‑열(open‑close) 반복’ 과정을 도입한다. 구체적으로, 규칙의 단순성을 보장하기 위해 최대 규칙 수를 4개로 제한하고, 적응형 오차 임계값(≈23)을 설정하였다. 이때 ‘닫힌 세계 가정(CWA)’과 ‘열린 세계 가정(OWA)’를 교차 적용해 초기 정보의 불완전성을 보완하고, 점진적으로 퍼지 입자의 정밀도를 향상시켰다.
세 번째 단계는 ‘거친 집합(Rough Set Theory, RST)’을 이용한 근사 분석이다. RST는 속성‑값 테이블을 기반으로 하위 및 상위 근사집합을 정의하고, 판별 행렬을 통해 최소 속성 집합(디펜던시 규칙)을 추출한다. 저자는 루게온 값을 1~5(매우 낮음~매우 높음)와 6(불확정)으로 구분하는 심볼릭 레벨링을 수행하고, 이를 SOM과 결합해 5단계 심볼릭 군집을 도출하였다.
연구 대상은 이란 Shivashan 댐 지역으로, 20개 보링에서 789개의 루게온 데이터가 수집되었다. 두 가지 실험 시나리오를 설정하였다. 첫 번째는 보링 위치(x, y, z)를 입력으로 3차원 등고선(iso‑lugeon) 그래프를 생성하는 것이며, 두 번째는 지표고(Z), 시험 구간 길이(ΔL), 암석 품질(RQD), 풍화 정도(TWR) 등을 입력 변수로 하여 투과성 예측 모델을 구축하는 것이다.
SOM‑NFIS 기반 모델은 Z=1160, 1180, 1190, 1200 m에서 각각의 등고선을 성공적으로 재현했으며, RST 기반 심볼릭 모델은 1~5 단계로 구분된 투과성 분포를 시각화하였다. NFIS 결과는 RQD가 증가할수록 루게온 값이 감소하고, 고도가 높을수록 루게온이 상승하는 비선형 관계를 명확히 보여준다. RST 결과는 좌측 은방에서 투과성이 낮고 우측에서 높다는 지질학적 해석을 지원한다.
논문의 주요 기여는 다음과 같다. ① 크리스프‑퍼지‑거친 집합의 3중 입자화 구조를 제안하여 데이터 전처리, 규칙 추출, 불확실성 관리라는 세 가지 핵심 과제를 동시에 해결한다. ② ‘규칙의 단순성’과 ‘오차 임계값’이라는 두 명시적 기준을 통해 입자화 수준을 정량적으로 제어함으로써 알고리즘의 안정성을 확보한다. ③ 실제 현장 데이터에 적용해 투과성 변동을 효과적으로 파악하고, 인간이 이해하기 쉬운 간결한 규칙을 도출한다.
한계점으로는 입자화 단계에서 무작위 초기화와 파라미터 선택이 결과에 미치는 영향을 정량적으로 분석하지 않았으며, 대규모 데이터셋에 대한 확장성 검증이 부족하다는 점을 들 수 있다. 향후 연구에서는 파라미터 자동 최적화, 다중 데이터 소스 통합, 실시간 모니터링 적용 등을 통해 방법론을 확장할 필요가 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기