정보 은닉 기술 종합 가이드
초록
본 튜토리얼 논문은 스테가노그래피와 디지털 워터마킹의 역사적 배경을 소개하고, 텍스트·이미지·오디오 등 다양한 매체와 파일 시스템·네트워크 프로토콜에 적용되는 정보 은닉 기법들을 개괄적으로 정리한다. 스테가노그래피와 암호학의 차이점, 순수·비밀키·공개키 스테가노그래피 프로토콜, 그리고 구현 시 고려해야 할 보안 원칙들을 설명한다.
상세 분석
이 논문은 정보 은닉 분야의 입문자에게 폭넓은 개요를 제공한다는 점에서 의의가 크다. 먼저 고대 그리스·로마 시절부터 제2차 세계대전까지 이어지는 스테가노그래피의 역사적 사례를 풍부하게 인용하여, 은닉 기법이 단순한 암호화와는 별개의 ‘숨김’ 메커니즘임을 강조한다. 특히 트리트미우스의 ‘아베 마리아’ 암호와 같은 고전적인 텍스트 은닉 방법을 상세히 서술함으로써, 현대 디지털 환경에서도 텍스트 기반 은닉이 여전히 활용 가능함을 시사한다.
논문은 스테가노그래피와 암호학을 비교하면서, 두 기술이 상호 보완적이라는 점을 강조한다. 암호화는 전송 중 데이터 자체를 보호하지만 복호화 후에는 평문이 노출되는 반면, 스테가노그래피는 존재 자체를 은폐함으로써 탐지 위험을 감소시킨다. 이러한 차이를 바탕으로 ‘스테가노그래피 + 암호화’ 복합 방식을 권장하는 논리 전개는 실무적 가치를 제공한다.
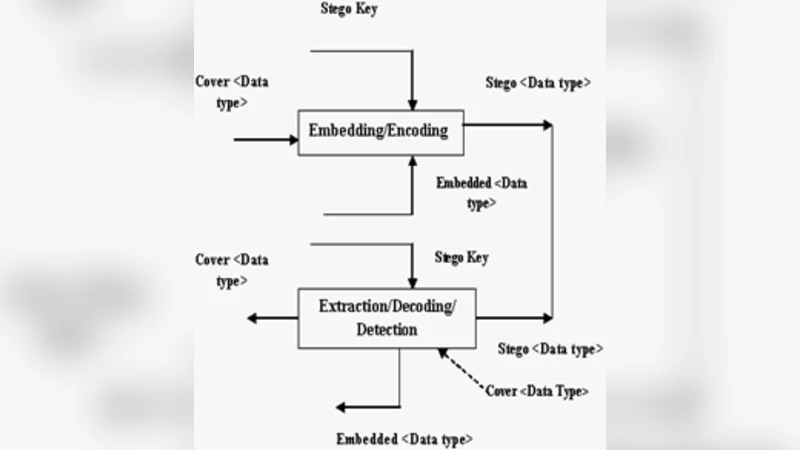
프로토콜 분류에서는 순수 스테가노그래피, 비밀키 스테가노그래피, 공개키 스테가노그래피 세 가지 모델을 제시한다. 순수 모델은 키 교환이 없으므로 가장 취약하지만 구현이 간단하고, 비밀키 모델은 공유된 스테고키를 통해 은닉 정보를 복원한다. 공개키 모델은 공개키 암호와 동일한 수학적 기반을 이용해 키 관리 문제를 해결한다는 점에서 가장 강력하지만, 구현 복잡도가 높다. 이러한 구분은 연구자와 엔지니어가 적용 환경에 맞는 모델을 선택하도록 돕는다.
매체별 은닉 기법 파트에서는 이미지(LSB 삽입, DCT 변조), 오디오(주파수 대역 변조), 텍스트(공백·문자 간격 조절), 파일 시스템(숨김 파티션·클러스터 활용), 네트워크 프로토콜(IP 식별자·시퀀스 번호) 등 구체적인 사례를 제시한다. 특히 IP 헤더와 TCP 시퀀스 번호에 ASCII 값을 매핑하는 방법은 실용적이면서도 탐지 회피가 어려운 기법으로 평가된다. 그러나 논문은 이러한 기법들의 정량적 보안 분석(예: 용량 대비 탐지 확률, 변조에 대한 강인성)이나 최신 스테가노그래피 연구(예: 딥러닝 기반 은닉·복원)에는 언급하지 않아 최신 동향 파악에 한계가 있다.
전반적으로 논문은 서술이 다소 산만하고 오탈자가 많으며, 각 기법에 대한 구현 코드나 실험 결과가 부재하다. 하지만 정보 은닉의 기본 개념과 다양한 적용 분야를 한눈에 파악할 수 있게 정리한 점은 교육용 자료로서 충분히 활용 가능하다. 향후 연구에서는 보안 강도 평가, 스테가노그래피와 머신러닝의 결합, 그리고 법적·윤리적 이슈에 대한 논의가 추가될 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기