하위집단 가중치 추정을 위한 바텀‑k 스케치와 새로운 추정기
본 논문은 대규모 가중치 데이터셋에서 하위집단(조건부) 가중치를 효율적으로 추정하기 위해 바텀‑k 스케치를 활용한다. 저자는 Horvitz‑Thompson 원리를 변형한 두 가지 추정기(RC, SC)를 제안하고, 전체 가중치가 알려졌을 때와 없을 때 각각 최적에 가까운 무편향 추정값과 신뢰구간을 제공한다. 또한 Pareto 분포를 이용한 실험을 통해 제안 방법이 기존 방법보다 분산이 작고 정확도가 높음을 입증한다.
저자: Edith Cohen, Haim Kaplan
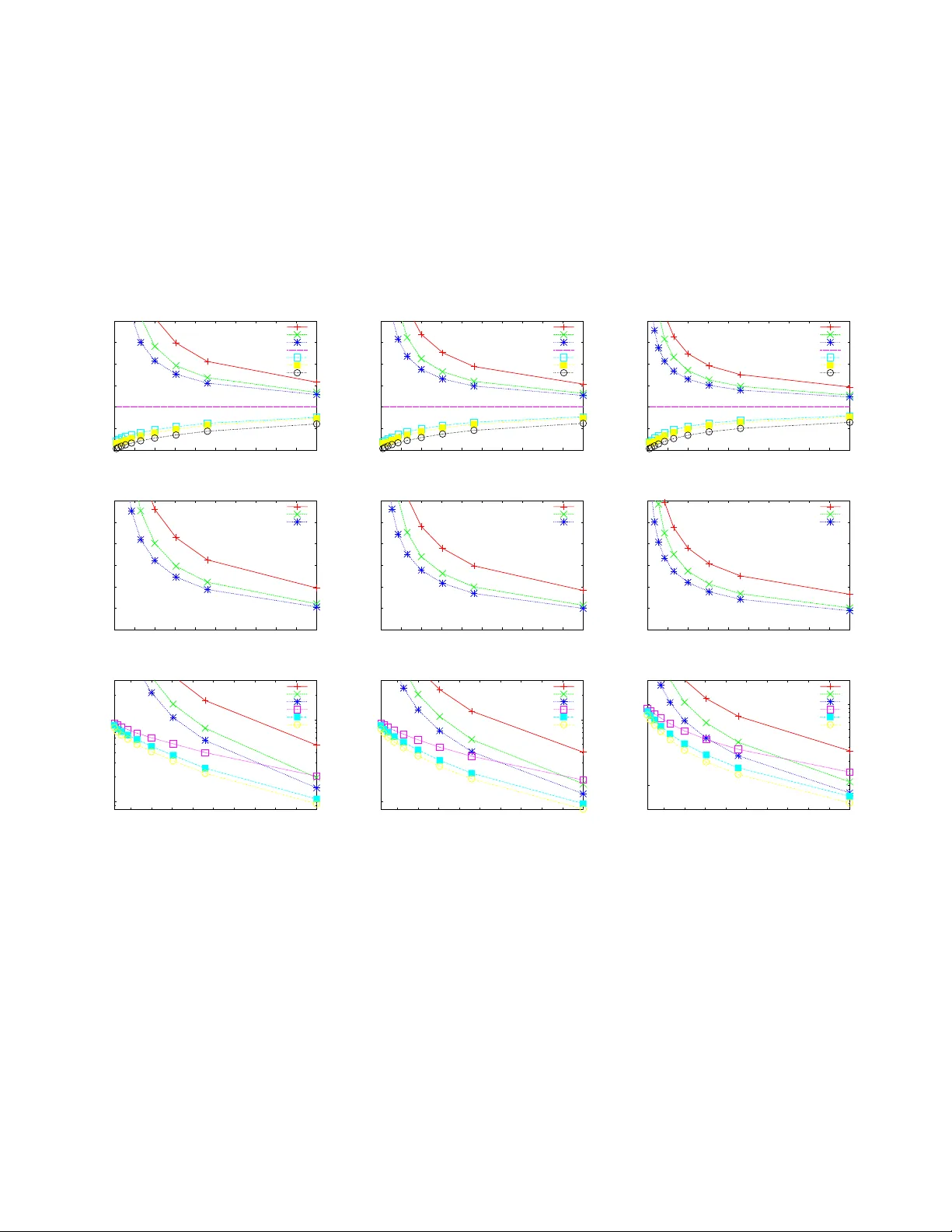
논문은 대규모 가중치 데이터셋에서 “하위집단 가중치”라는 기본 집계값을 효율적으로 추정하는 방법을 제시한다. 하위집단은 레코드 속성에 대한 임의의 프레디케이트로 정의되며, 그 가중치 w(J)=∑_{i∈J}w(i)는 네트워크 트래픽, 인구통계 등 다양한 분야에서 핵심적인 통계량이다. 기존에는 전체 데이터를 저장하거나, 단순 샘플링을 통해 근사값을 얻었지만, 데이터 규모가 커짐에 따라 이러한 접근법은 비용이 과다하거나 정확도가 떨어진다.
바텀‑k 스케치는 각 아이템 i에 대해 무작위 순위 r(i)를 할당하고, 가장 작은 k개의 순위를 가진 아이템을 저장한다. 순위 분포 f_w(x)는 아이템의 가중치 w에 따라 달라지며, 특히 exponential 분포 f_w(x)=w·e^{-wx}를 사용하면 ws(Weighted Sampling without replacement)와 동일한 샘플링 확률을 얻는다. 이때 스케치는 (r_i, w_i) 쌍과 함께 (k+1)번째 최소 순위 r_{k+1}을 포함한다. r_{k+1}은 스케치에 포함되지 않은 아이템들의 순위 분포를 재구성하는 데 필요하다.
핵심 문제는 “각 아이템이 스케치에 포함될 확률을 알 수 없으므로 전통적인 Horvitz‑Thompson(HT) 추정기를 바로 적용할 수 없다”는 점이다. 저자는 이 문제를 해결하기 위해 샘플 공간을 아이템별 파티션으로 나누고, 각 파티션 내에서 포함 확률을 계산하는 HTp(HT on a partitioned sample space) 방법을 제안한다. 이를 통해 두 가지 새로운 추정기를 도출한다.
1. **Rank Conditioning (RC) 추정기**
- 전체 가중치 w(I)가 제공되지 않을 때 사용한다.
- 각 아이템 i에 대해 조정 가중치 a_i = w(i) / Pr
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기