소프트웨어 그래프에서 드러나는 입·출 차별 현상과 프로그래머 인식 모델
본 논문은 객체지향 프로그램의 타입 의존성을 그래프로 모델링하고, 인디그리(입력 차수)는 파워‑law, 아웃디그리(출력 차수)는 지수‑분포를 보이는 현상을 확인한다. 프로그래머가 자신이 현재 작업 중인 타입의 출력 차수는 인식하지만, 다른 타입이 자신을 참조하는 입력 차수는 인식하지 못한다는 가정 하에, 노드 분할과 선호적 연결을 결합한 단순 생성 모델을 제안한다. 시뮬레이션 결과는 12개의 Java 프로젝트에서 14가지 의존성 메트릭에 대해 …
저자: G. J. Baxter, M. R. Frean
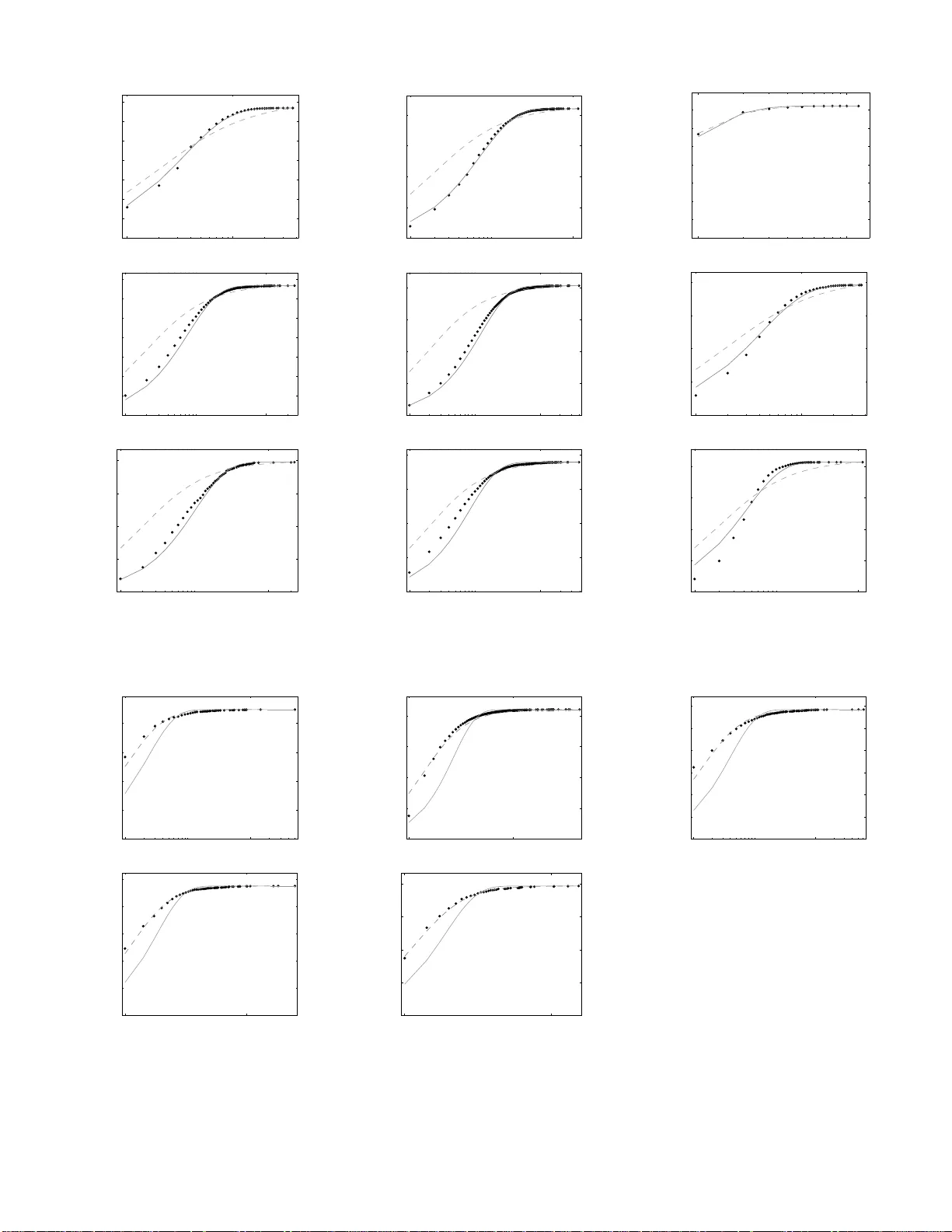
본 논문은 객체지향 소프트웨어의 타입 의존성을 유향 그래프로 모델링하고, 그 그래프의 차수 분포가 나타내는 특이성을 심층적으로 탐구한다. 서론에서는 소프트웨어가 복잡한 상호 의존 구조를 갖는다는 점을 강조하고, 타입을 노드, 의존성을 엣지로 보는 다양한 메트릭(필드, 메서드 파라미터, 상속, 구현 등)을 소개한다. 기존 연구들에서 인디그리(다른 타입이 해당 타입을 참조하는 횟수)는 파워‑law 형태, 아웃디그리(해당 타입이 다른 타입을 참조하는 횟수)는 지수‑분포 형태를 보인다는 현상이 보고되었으며, 이는 프로그램 언어와 메트릭에 관계없이 일관되게 나타난다. 이러한 차이는 단순히 통계적 우연이 아니라, 코드 작성 과정에서 프로그래머가 어떤 정보를 의식하고 어떤 정보를 무시하는가에 기인한다는 가설을 제시한다.
모델링 섹션에서는 두 가지 기본 행동을 정의한다. 첫 번째는 “엣지 추가”이며, 이는 현재 작업 중인 타입(아웃디그리가 큰 노드)에서 새로운 의존성을 만든다. 선택 확률은 현재 아웃디그리 v_i를 전체 엣지 수 t로 나눈 비율(v_i/t)이다. 두 번째는 “노드 분할”이며, 타입이 너무 복잡해지면 프로그래머는 이를 두 개의 작은 타입으로 나눈다. 분할은 확률 γ로 발생하고, 부모 노드의 아웃디그리를 r(0≤r≤v_i)와 v_i‑r+1 두 부분으로, 인디그리를 s(0≤s≤w_i‑1)와 w_i‑s 두 부분으로 나눈다. 분할 후에는 부모와 자식 사이에 새로운 엣지가 생성돼 모든 노드가 최소 하나의 입력·출력 엣지를 유지한다. 이 과정은 아웃디그리와 인디그리의 선택 메커니즘을 동일하게 유지하지만, 분할 규칙이 오직 아웃디그리와만 연관돼 있다는 점에서 비대칭성을 만든다.
수학적 분석에서는 차수별 노드 수 C_m(아웃디그리 m)와 그 변화량을 식 (1)로 전개하고, 정규화된 차수 비율 f_m = C_m/k를 도출한다. 결국, 안정 상태에서 f_m = γ(1‑γ)^{m‑1}이 되며, 이는 기하급수적 감소, 즉 지수‑분포와 동일하다. 인디그리의 경우, 선택 확률이 인디그리 w_i에 비례하지만 분할이 인디그리와 무관하게 이루어지므로, 기존의 선호적 연결 모델과 동일하게 파워‑law 형태 g_n ∝ n^{-α}가 도출된다. 여기서 α는 γ와 초기 조건에 따라 2~3 사이의 값을 가진다.
시뮬레이션에서는 t_final을 10^5~10^6 단계까지 진행하고, γ를 0.05~0.3 범위에서 조정했다. 결과는 실제 12개의 Java 프로젝트(총 14가지 메트릭)에서 관측된 차수 분포와 높은 일치도를 보였다. 인디그리 플롯은 로그‑로그 축에서 직선 형태를, 아웃디그리 플롯은 로그‑선형 축에서 직선을 이루어, 모델이 제시한 두 분포 형태를 실증적으로 확인했다. 특히, NetBeans, Eclipse SDK, OpenOffice 등 대규모 프로젝트에서도 동일한 패턴이 재현되었으며, γ≈0.12가 평균적으로 가장 좋은 적합도를 제공했다.
논의에서는 모델의 장점과 한계를 평가한다. 장점은 프로그래머의 인지적 제한을 직접 반영함으로써, 복잡한 소프트웨어 구조의 통계적 특성을 간단한 규칙으로 설명한다는 점이다. 또한, 기존의 GNC 모델이나 순수 선호적 연결 모델이 설명하지 못한 아웃디그리의 지수적 감소를 자연스럽게 재현한다. 한계로는 실제 개발 과정에서 발생하는 리팩터링, 인터페이스 추출, 다중 상속, 테스트 코드 등 다양한 코드 변형을 단일 분할 규칙으로 단순화했다는 점이다. 또한, 모델 파라미터 γ가 프로젝트마다 다소 차이를 보이지만, 그 원인을 코드베이스 규모, 개발자 수, 도메인 특성 등으로 명확히 규명하지 못했다.
결론에서는 프로그래머가 “출력 차수”를 직접 제어하고 “입력 차수”는 간접적으로만 영향을 받는다는 인지적 가설이, 실제 소프트웨어 그래프에서 관측되는 차수 비대칭을 설명하는 충분한 메커니즘임을 강조한다. 향후 연구 방향으로는 버전 관리 로그를 이용한 동적 그래프 분석, 다른 프로그래밍 언어와 패러다임에 대한 확장, 그리고 개발자 협업 네트워크와의 연계 모델링을 제시한다. 이 연구는 소프트웨어 구조 분석에 새로운 관점을 제공하며, 코드 품질 평가 및 리팩터링 자동화 도구 개발에 실용적인 통찰을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기